
Introduction
Education continues its ongoing evolution while foreign language instruction faces distinctive challenges to match learning materials with student capabilities (Kavrayici et al., 2025). Learning outcomes, together with curriculum development and student motivation, benefit from readability assessment because it plays an essential role in this process. The German language presents special learning challenges because of its complex grammar and syntax, so educational materials must be suitable for student proficiency levels.
The Flesch Reading Ease and Flesch-Kincaid Grade Level represent traditional readability formulas which measure text complexity through sentence length and word frequency analysis. The application of these metrics in foreign language settings proves inadequate because they were created for native speakers while focusing on basic text characteristics. These assessment tools do not detect essential linguistic complexities which are vital for language learners to understand. Artificial intelligence (AI) advancements have brought new possibilities for evaluating text complexity. The language analysis and generation capabilities of ChatGPT provide more detailed insights than traditional formulas (Huang et al., 2024;Shaitarova et al., 2024), and AI-powered systems have the potential to transform readability assessment by evaluating idiomatic expressions, discourse coherence, and grammatical intricacies, which traditional metrics do not measure.
This research investigates how ChatGPT performs in evaluating the readability of German foreign language textbooks. The research compares AI-generated assessments to established formulas to determine whether AI tools provide a more precise and linguistically sensitive alternative. The study advances the discussion about AI implementation in foreign language education while examining how AI could transform material selection and curriculum planning processes. These perspectives are essential for understanding the evolving role of AI in language teaching.
Literature Review
Readability plays a vital role in foreign language instruction by aligning text complexity—determined by lexical, syntactic, and textual features—with learners' proficiency levels, thereby supporting vocabulary acquisition, grammar learning, and overall academic success (N. T. D.Nguyen & Lam, 2023; Omer & Al-Khaza'leh, 2021). The following sections explore its pedagogical significance and practical applications.
Readability in Language Pedagogy
Readability assessment enables teachers to select materials that match students’ proficiency levels, which supports language learning success and sustains motivation (Kamal, 2019; Kasule, 2011; Maqsood et al., 2022; Nassiri et al., 2018). By aligning text complexity with learner abilities, it also fosters vocabulary acquisition and grammatical development (Brooks et al., 2021; Hu et al., 2022;Parhadjanovna, 2023). Reading tasks support students in developing monologue and text response skills in language classes (Gordeeva &Usupova, 2023;Zheleznova, 2019). Individualized instruction, grounded in sound teaching principles, improves reading abilities in English as a foreign language (Chen, 2023;Noviyenty, 2017; Zhu, 2024). Effective readability integration requires understanding learners’ background knowledge, cognitive styles, and engagement patterns. Therefore, readability should be considered in conjunction with other pedagogical factors when designing curricula.
The text complexity can be evaluated using readability indices such as Gunning Fog and Flesch-Kincaid to determine appropriate student difficulty levels (Bakuuro, 2024). Traditional first language readability indices do not provide accurate predictions of EFL difficulty. According to Brown (1998), linguistic features such as sentence syllable count, word frequency, and function word percentage proved to be better indicators of EFL difficulty which indicates the requirement for EFL-specific readability indices. The potential exists for AI systems to enhance conventional educational methods while simultaneously reducing teacher workload. Language education represents a domain where readability plays a crucial role in ensuring material suitability and learner comprehension.
Traditional Readability Metrics: Approaches and Limitations
1. Flesch-Kincaid Grade Level (F-K) (Flesch, 1948)
Created by Rudolf Flesch (1948) and later refined by J. Peter Kincaid et al. (1975), this metric calculates readability using the following formula. It has been applied across various contexts to estimate the readability of English texts:
Grade Level = (0.39 ×W) + (11.8 ×S) - 15.59
-W= Average number of words per sentence
-S= Average number of syllables per word
2. Automated Readability Index (ARI) (Senter & Smith, 1967)
Automated Readability Index (ARI): Developed by Senter and Smith (1967) for the U.S. Air Force, this formula estimates the U.S. school grade level required to understand a text by calculating the number of characters per word and words per sentence, unlike other formulas that rely on syllable counts:
ARI = (4.71 ×C) + (0.5 ×W) - 21.43
-C= Average number of characters per word
-W= Average number of words per sentence
3.Läsbarhetsindex(LIX) (Björnsson, 1968)
Proposed by Björnsson in 1968, this formula was initially developed for Swedish texts but has proven effective across multiple languages. It calculates readability based on average sentence length and the percentage of long words (more than six characters).
LIX = (W/S) + (L/W× 100)
-W= Number of words in the text
-S= Number of sentences in the text
-L= Number of long words (more than 6 characters)
4. Simple Measure of Gobbledygook (SMOG) (McLaughlin, 1969)
Created by Harry McLaughlin (1969), SMOG evaluates text complexity by counting polysyllabic words (three or more syllables) per 100 words. It is particularly valued for its high correlation with actual text comprehension.
SMOG = 1.0430 ×√(P× (30/N)) + 3.1291
-P= Number of polysyllabic words (words with three or more syllables)
-N= Number of sentences in the sample
5. Coleman-Liau Index (CLI) (Coleman & Liau, 1975)
Developed by Coleman and Liau (1975), this formula measures readability based on the average number of letters and sentences per 100 words, and it is expressed as follows:
CLI = (0.0588 ×L) - (0.296 ×S) - 15.8
-L= Average number of letters per 100 words
-S= Average number of sentences per 100 words
Higher scores indicate more complex texts.
Table 1. Readability Level Distribution
| Readability Level | F–K | ARI | LIX | SMOG | CLI |
| Very Easy | ≤ 5 | 1-5 | < 25 | ≤ 5 | ≤ 6 |
| Easy | 6-8 | 6-8 | 25-35 | 6-8 | 7-9 |
| Moderate | 9-12 | 9-12 | 35-45 | 9-12 | 10-12 |
| Difficult | 13-16 | 13-16 | 45-55 | 13-16 | 13-15 |
| Very Difficult | 17+ | 17+ | > 55 | 17+ | 16+ |
Readability metrics function as essential evaluation tools to measure written content complexity and accessibility levels. Writers and educators use these measurements to verify their content aligns with the reading capabilities of their target audience. This research investigates the five-level readability score classification system together with its real-world applications. The five-level classification system of very easy, easy, moderate, difficult and very Difficult provides a detailed text complexity analysis which exceeds traditional three-level systems. The extended classification system enables exact identification of both audience group and reading requirements for written materials. A three-level system typically places text into basic categories of 'difficult' or 'easy' but the five-level system enables better distinctions between undergraduate-level content (Difficult) and graduate/professional level material (Very Difficult). The detailed classification system shows its greatest value when evaluating academic or technical documents because small variationsin complexity directly affect reader understanding. Multiple well-known readability metrics (Coleman Liau Index, Flesch Kincaid Grade Level, ARI, and SMOG) work together within this system to create a complete evaluation of text accessibility through various readability dimensions.
The research concentrates on traditional readability metrics instead of machine learning methods for three main reasons.
1.Proven track record: These formulas have been extensively validated through decades of empirical research
2.Transparency: The mathematical foundations and calculations are clear and reproducible
3.Language independence: These metrics rely on surface-level text features that can be applied across different languages without requiring large training datasets
4.Computational efficiency: Traditional formulas can be implemented with minimal computational resources
5.Interpretability: The results are easily understood by educators and researchers without requiring expertise in machine learning
The application of machine learning methods for readability assessment demonstrates potential but needs extensive language-specific training data and fails to adapt between languages and contexts. Traditional readability metrics enable consistent readability assessment across languages because they establish a well-defined framework.
The Flesch-Kincaid readability assessment tool along with other traditional metrics remains widely used to measure text complexity yet fails to accurately measure text difficulty because it only evaluates quantifiable characteristics of word length and sentence structure (DuBay, 2004). The formulas concentrate on surface-level characteristics while neglecting complex linguistic elements that affect comprehension, especially in online texts, together with technical documentation and domain-specific content (Crossley et al., 2017). The Flesch-Kincaid and LIX metrics represent classical readability formulas that evaluate text readability through word and sentence length measurements and, therefore, remain popular in educational settings despite their known restrictions (Chall, 1996). The combination of cognitive and semantic measures with human qualitative evaluations provides better readability insights,but traditional metrics neglect domain-specific jargon and contextual complexities (Redish, 2000; Redmiles et al., 2018).
Studies have investigated enhanced readability assessment methods that combine natural language processing with crowd-sourced ratings and machine learning techniques (Crossley et al., 2017). These newer methods demonstrate stronger predictive capabilities than traditional formulas by evaluating text-base processing, situation models, and cohesion (Crossley et al., 2017). Tools like Coh-Metrix provide extensive linguistic analyses that address several limitations of traditional metrics, especially their inability to adapt to adult or technical texts, where layout and retrieval aids significantly affect readability (Crossley et al., 2017; Redish, 2000). Traditional metrics, in contrast, focus primarily on quantifiable features such as word and sentence length while overlooking critical comprehension factors, like reader background and text purpose (Plung, 1981). The emerging methods that combine cognitive and semantic analysis with qualitative assessments show potential for improving readability evaluation, but computational models for readability assessment require further development. The connection between computational research and educational and psychological insights remains essential for future developments, according to Vajjala(2022). because new methods require substantial computational power and standardized methods to evaluate subjective reader responses across different populations.
AI-Inspired and Machine Learning Approaches to Readability
Traditional readability metrics serve as basic assessment tools; however, researchers have developed new methods that include extra linguistic elements in recent years. Advanced methods assess readability through the evaluation of word frequency together with morphological analysis and parse tree depth to generate detailed readability results. The field has received substantial advancement through machine learning approaches. Support Vector Machines (SVMs) have been applied to study lexical, syntactic, and morpho-syntactic features in research by Petersen and Ostendorf (2009). The analysis of sequential text complexity has been developed through neural network models that utilize Long Short-Term Memory (LSTM) and Recurrent Neural Networks (RNNs) (Hochreiter &Schmidhuber, 1997; Lo Bosco et al., 2019).
Language modeling techniques have proven essential for readability prediction tasks (Collins-Thompson & Callan, 2004; Si & Callan, 2001). The integration of syntactic complexity features, including parse tree height and entity coherence, has been studied by researchers such as Schwarm and Ostendorf (2005) and Heilman et al. (2007). The analysis of statistical and traditional measures combines to evaluate features including noun phrases, verb phrases, and subordinate clauses per sentence, according to Schwarm and Ostendorf (2005). Artificial Neural Networks (ANNs) improve readability assessment through their analysis of lexical and syntactic indicators to automate text complexity evaluation. The method delivers an automated solution which replaces traditional formulas while providing flexible application across different situations (Samawi et al., 2023). The methods show promise for application in German texts because they have shown primarily English usage but demonstrate potential use in other languages with diverse linguistic structures and complex syntax. The Large Language Models (LLMs), including ChatGPT, present researchers with a fresh method to evaluate readability. The analysis of texts by LLMs through holistic methods allows them to detect both explicit and implicit indicators of complexity in addition to traditional linguistic features and statistical models. Their syntactic analysis, together with semantic evaluation and discourse-level processing, allows for flexible context-specific assessments. I will use ChatGPT to examine its potential by running the following prompt for text classification into predetermined readability categories:
“Analyze the readability of the following text and categorize it into one of the five levels: Very Easy, Easy, Moderate, Difficult, or Very Difficult. Consider factors such as sentence complexity, vocabulary difficulty, grammatical structures, and overall comprehensibility for a general audience.”
The flexibility of machine learning-based approaches, including LLMs, does not eliminate certain limitations they encounter. The systems depend on restricted datasets and make use of minimal classifiers, and analyze entire texts instead of sentences. The effectiveness of LLMs to detect specific linguistic features across different proficiency levels remains unknown because they lack explicit readability assessment training (Pitler &Nenkova, 2008). The established readability formulas maintain their proven reliability and transparency which makes traditional metrics essential for cross-linguistic assessment.
Research Objectives and Questions
The research investigates how AI-based methods, including ChatGPT, compare to traditional readability metrics for evaluating German foreign language textbook readability. The research examines whether AI tools deliver superior text complexity evaluation compared to standard measurement formulas.
Key Research Questions:
1. How do readability scores generated by ChatGPT compare to those obtained from traditional readability formulas?
2. Can AI tools like ChatGPT provide more accurate and linguistically insightful assessments of text complexity in German foreign language textbooks?
3. What implications do AI-based readability assessments have for textbook selection and
foreign language education?
The research investigates how AI readability tools can benefit education through their strengths and weaknesses while exploring their practical educational uses. The research results will expand knowledge about AI's function in language education, educational content creation, and instructional methods.
Methodology
This study uses a methodological framework that compares ChatGPT with traditional readability metrics to evaluate the readability of German foreign language textbooks. The methodology is designed to provide a thorough and systematic evaluation by using both quantitative and qualitative approaches to analyze and compare the effectiveness of various readability assessment tools.
The research design implements a comparative analytical research design to evaluate the effectiveness of ChatGPT's readability assessment capabilities relative to traditional evaluation methods. The research includes a controlled evaluation between ChatGPT-generated linguistic outputs and results from established readability formulas including Flesch Kincaid Grade Level (Flesch, 1948), ARI (Automated Readability Index) (Senter & Smith, 1967), LIX (Björnsson, 1968), SMOG (Simple Measure of Gobbledygook) (McLaughlin, 1969),and Coleman Liau index (Coleman & Liau, 1975). Traditional measurement tools such as sentence length and word frequency assessment have been used for a long time; however,they do not detect the sophisticated linguistic elements found in educational texts.
Data Collection: Textbook Selection
The research utilizes a carefully curated collection of German textbooks designed for foreign students to compare educational materials across various learning environments and skill levels. The corpus consists of four textbooks which include two publications from the Turkish national education ministry and two German educational publisher materials at various CEFR (Common European Framework of Reference for Languages) levels. The corpus selection process followed specific criteria to establish both the validity and reliability of the corpus. The analysis required textbooks to display explicit CEFR level alignment because this enabled proper readability comparisons between different proficiency levels. The analysis focused on contemporary language teaching practices because the textbooks needed to be active in their respective educational systems at the time of analysis. The analysis focused on recent editions which appeared during the previous five years to study modern educational methods and teaching approaches.
The inclusion of textbooks from both Turkish and German educational contexts provides an opportunity to examine how different educational traditions and publishing approaches might influence text complexity and readability. This dual-context approach also allows for the investigation of potential cultural and pedagogical differences in text presentation and complexity progression across CEFR levels.
The textbook selection process focused on materials which received official recognition from their respective educational authorities. The Turkish textbooks received approval from the Ministry of National Education while German textbooks originated from established educational publishers who specialize in foreign language education materials.
The methodically organized corpus establishes a reliable base for studying readability patterns between educational settings and proficiency points which helps explain foreign language education material text complexity management. Following textbooks are selected:
Table 2. Selected Textbooks
| Textbook Name | CEFR Level | Year |
| Deutsch für Gymnasien Schülerbuch (Zabun, 2020) | A1.1 | 2020 |
| Kontext Deutsch als Fremdsprache (Koithan et al., 2021) | B1 | 2021 |
| Beste Freunde (Georgiakaki et al., 2019) | A1.2 | 2022 |
| Mein Schlüssel zu Deutsch (Aksu Güney et al., 2023) | B1.2 | 2023 |
Sample Research Corpus Selection
The common data selection method of Simple random sampling (SRS) has alternative approaches which provide better efficiency and performance. Active learning minimizes text data labeling expenses, especially in cases with imbalanced classes through document-specific targeting instead of random sampling (Miller et al., 2020). The modified Extreme and Double Extreme Ranked Set Sampling schemes deliver more powerful testing results and efficient estimates than SRS does according to Samawi et al. (2023). Bhushan et al. (2023) developed an efficient class of estimators which performs better than current methods for variance estimation in SRS. Model-based clustering through data mining techniques enables national surveys with small sample sizes to develop homogeneous strata which boosts sampling efficiency by 1.7 times above SRS (Parsaeianet al., 2021). The alternative sampling methods present researchers with more efficient and cost-effective data collection and analysis options which perform better than traditional SRS methods in different research settings.
Table 3. "Deutsch für Gymnasien Schülerbuch" Texts
| Sample | Page | Text |
| 1 | 55 | Meine Mutter kocht jeden Tag. Gemüse ist unser Hauptgericht. Obst ist unsere Nachspeise. Sie meint: „Gemüse und Obst sind sehr gesund.“Ab und zu macht sie auch Hamburger und Pommes. ber die Pommes bratet sie nie im Öl. Meine Mutter backt sie im Ofen. Sie meint: „Gesund leben ist auch abhängig vom Essen. Besonders zu viel Fett schadet der Gesundheit.“ |
| 2 | 80 | Er heiβt Florian. Er treibt immer Sport und ist ein Mitglied von einer Mannschaft. Die Mannschaft trainiert sehr oft zusammen. Manchmal traineren sie in der Woche vier Mal, manchmal drei Mal. Florian verpasst fast nie das Training, auβer er ist krank. Florian wird selten krank. Er liebt das Spiel und das Training. |
| 3 | 90 | Nächste Woche ist Weihnachten. Frau Müller möchte einkaufen gehen. Sie will für ihre Familie Geschenke kaufen. In der Woche hat sie kaum Zeit. Am Wochenende ist die ganze Familie zusammen. Sie muss eine Lösung finden. Ihre Freundin sagt: „Kauf doch online! Du kannst Zeit sparen.“ Du wählst aus und sie liefern dir deine Geschenke nach Hause. Frau Müller findet die Idee toll. Sie setzt ich gleich vor den PC und sucht Geschenke für ihre Familie. Sie kauft für Herrn Müller eine Krawatte. Für Susi eine Kette und für Thomas eine Armbanduhr. |
Table 4. "Kontext Deutsch als Fremdsprache" Texts
| Sample | Page | Text |
| 4 | 159 | Naturparadiese und Wildnis sind viel näher, als man denkt, auch in Deutschland. Nur das Nötigste in den Rucksack packen, sich aus dem, was man in der Natur findet, ein Lager für die Nacht bauen und das Abendessen über dem Feuer zubereiten. All das ist möglich, wenn man weiß, wie. Und das erfährt man in diesem Ratgeber. Die Autorin ist Überlebenstrainerin und Expertin, wenn es um Überlebensstrategien in der Natur geht: Outdoor- Leben, Gefahren, Heilmittel aus der Natur. Dinge, auf die man nicht verzichtensollte. Rezepte und Antworten auf die Frage, was erlaubt ist und was nicht. Raus aus dem Alltag, rein in die Natur! |
| 5 | 166 | Das Ferne und Unbekannte zu erreichen, galt schon immer als Beweis für menschliche Leistungsfähigkeit. Dass es nun ausgerechnet der Rote Planet ist, liegt an den vielen Erkenntnissen, die Wissenschaftler in den letzten Jahren über den Mars gewonnen haben. Diese machen deutlich: Der Mars hat etwas zu bieten, nämlich nicht nur eine vielfältige Oberfläche, sondern auch eine Atmosphäre. Und spätestens seitdem die Sonde Phoenix nachgewiesen hat, dass es gefrorenes Wasser auf dem Roten Planeten gibt, sind die Forscher weltweit begeistert. Wasser ist nun einmal die Quelle allen Lebens. Möglicherweise gab es früher Leben auf dem Mars oder es existiert heute immer noch in irgendeiner Form, die wir nicht kennen. Je mehr Erkenntnisse wir darüber haben, umso mehr Wissen erhalten wir über das ganze Sonnensystem. Vielleicht werden wir Menschen den Mars besiedeln. Das ist zwar noch Zukunftsmusik, gilt aber als sehr wahrscheinlich. Denn wir müssten uns in zeitlicher Hinsicht kaum umstellen: Ein Marstag dauert mit 24,6 Stunden kaum länger als ein Erdentag. Die Temperaturen sind im Vergleich zu anderen Planeten fast angenehm, jedoch für uns ziemlich extrem. Einerseits erreichen sie tagsüber 20 °C, andererseits sinken sie nachts auf unter minus 80 °C. Außerdem gibt es genügend Sonnenlicht auf dem Mars, um Solarenergie zu erzeugen. Leben auf dem Mars – ein Traum? Schon der deutsche Astronaut Alexander Gerst sagte: „Wir Menschen sind Entdecker. Sobald wir Flöße bauen konnten, sind wir über Flüsse gefahren. Sobald wir Schiffe bauen konnten, sind wir hinter den Horizont gesegelt. Jetzt können wir Raumschiffe bauen, also fliegen wir ins All.“ |
| 6 | 173 | Bildinhalte zu erfassen und auszuwerten ist wahrscheinlich die Fähigkeit im Bereich der künstlichen Intelligenz, die schon am weitesten perfektioniert ist. Beispiele dafür finden sich in fast jedem Smartphone: Die Lichtverhältnisse anpassen, den automatischen Fokus auf ein Gesicht legen, die Kamera genau dann auslösen, wenn man lächelt. So kommt man meistens zum perfekten Foto. Wer also ein Smartphone besitzt, verlässt sich beim Fotografieren auf KI. Und noch viel mehr Funktionen des Handys arbeiten damit. So merkt sich das Handy z. B., welche Funktionen und Einstellungen der Nutzer sehr oft wählt. Das Ergebnis: die morgendlich zugeschnittenen Nachrichten aus aller Welt, die Erinnerung an wichtige wiederkehrende Termine und die Ermittlung der idealen Weckzeit. Das alles spart dem Nutzer lange Sucherei und damit Zeit. |
Table 5."Beste Freunde" Texts
| Sample | Page | Text |
| 7 | 23 | Aktion „Schlafhandys sammeln": Viele Handys sind alt. Niemand braucht sie, sie„schlafen" zu Hause: Deshalb heißen sie„Schlafhandys" Jugendliche der Mittelschule Bergheim sammeln diese Handys. Eine Recycling-Firma zahlt vier Euro für ein Handy. Für 200 Handys bekommt die Schule genug Geld für einen neuen Computer. |
| 8 | 41 | Das ist der Berliner Reichstag am Platz der Republik 1. Hier arbeitet das Parlament von Deutschland. Für euch interessant ist sicherlich die Glaskuppel: Man kann in die Kuppel steigen und in den Himmel schauen. |
| 9 | 54 | Hi Lukas, ich habe lange nichts von dir gehört oder gelesen. Alles klar bei dir? Was machst du im August? Ich möchte wieder mit meinem Bruder an den Ammersee ins Feriencamp fahren. Das war doch ganz toll, oder? Also mir hat es gut gefallen. Ich möchte dann einen Surfkurs machen und SUPen*. Was das ist, siehst du auf dem Foto. Und? Bist du wieder dabei? Dann ruf mich an oder schreib mir. Bis bald, Paul |
Table 6. "Mein Schlüssel zu Deutsch" Texts
| Sample | Page | Text |
| 10 | 62 | Die Weltklimakonferenz COP 23 fand zum zweiten Mal im November 2017 in Bonn in den Zelten auf einer Blumenwiese statt. Dieses Gelände konnte erst vor wenigen Wochen vor der Konferenz renaturiert werden. Die Mitarbeiter haben Tag und Nacht ununterbrochen gearbeitet. Dabei wurden 59.000 Quadratmeter Rasenfläche wiederhergestellt. Die Flächeneinzäunung vom ehemaligen Veranstaltungsgelände musste beibehalten werden. Damit konnte der neu verlegte Rollrasen auch geschützt werden. Die COP 23 war die erste Weltklimakonferenz, das mit dem EMAS-Zertifikat offiziell als umweltfreundlich ausgezeichnet wurde. EMAS steht für „Eco Management and Audit Scheme“ (Das Gemeinschaftssystem für das Umweltmanagement und die Umweltbetriebsprüfung). Auf der Konferenz wurden alle Ziele und Maßnahmen für die Umwelterklärung dokumentiert. Die Ziele und Maßnahmen wurden von einem Umweltgutachter mehrere Tage vor Ort geprüft und schließlich bestätigt. |
| 11 | 114 | Nachdem ich mich entschieden hatte, meinen Master in „Geschichte der Wissenschaften“ zu machen, erfuhr ich, dass man vor der Aufnahme viele Prüfungen zu bestehen hat. Ich musste beweisen, dass ich neben sehr guten Deutsch- und Englischkenntnissen auch befriedigende Französischkenntnisse besaß. Zusätzlich habe ich während meines Studiums die Gelegenheit wahrgenommen, vier Semester lang einen Arabischkurs zu belegen. Diese Sprachen sind für Wissenschaftshistoriker wichtig, denn die meisten historischen Quellen sind ins Türkische nicht übersetzt worden. |
| 12 | 119-120 | Schüler sollen ihre Position in Gruppen einschätzen können, aber das geht nicht mit Berichtsbewertungen. Das ist ein großer Nachteil. Schulen vermitteln nicht nur Wissen oder Werte, sie bereiten die Schüler auch auf das weitere Leben vor. In der Gesellschaft werden unsere Leistungen immer bewertet. Schulen müssen diese Realität vor Augen halten. Es wäre unfair, wenn man die Schüler mit komplett anderen Kriterien bewertet und nicht auf diese Gesellschaft vorbereitet. Außerdem müssen Kinder lernen, mit Erfolg und Misserfolg umzugehen. Negative Rückmeldungen oder Leistungseinbrüche sind ein Teil des Lebens. Jeder sollte darauf vorbereitet werden. Problematisch sind nicht Ziffernnoten, problematisch ist, wenn man nicht mehr weiter weiß. |
Quantitative and Qualitative Analysis
The quantitative analysis involves compiling readability scores into datasets, followed by statistical methods such as mean comparisons, standard deviations, and correlation analyses. The goal is to compare ChatGPT-generated scores with those from traditional readability formulas to identify score patterns and evaluate relative effectiveness.
Prior to conducting these analyses, the normality of all readability metrics (F-K, ARI, LIX, SMOG, CLI) was tested using the Shapiro-Wilk test (Shapiro & Wilk, 1965) to ensure that the assumptions for parametric statistical techniques were met. The results confirmed that the data did not significantly deviate from normal distribution (p > .05 for all metrics), allowing the use of Pearson correlation and other parametric methods.
The qualitative dimension applies thematic analysis to ChatGPT’s feedback, focusing on the linguistic indicators it identifies in relation to the variables used in classical readability metrics. To ensure transparency and reproducibility, the exact prompt used to generate ChatGPT responses was:
“Analyze the readability of the following text and categorize it into one of the five levels: Very Easy, Easy, Moderate, Difficult, or Very Difficult. Consider factors such as sentence complexity, vocabulary difficulty, grammatical structures, and overall comprehensibility for a general audience.”
This mixed-methods approach enables a comprehensive assessment of the capabilities and limitations of both traditional formulas and AI-powered tools.
Findings/Results
The results of this study provide a comprehensive analysis of the readability scores generated by ChatGPT compared to traditional metrics formulas. This chapter presents both quantitative and qualitative findings, highlighting the effectiveness and accuracy of AI-driven tools in assessing text complexity.
Table 7. Comparative Analysis
| Sample | F-K | ARI | LIX | SMOG | CLI | ChatGPT | ChatGPT Score |
| 1 | 3.27 | 3.63 | 20.45 | 6.46 | 6.78 | Very Easy | 1 |
| 2 | 3.87 | 5.38 | 34.35 | 5.93 | 9.05 | Very Easy | 1 |
| 3 | 3.22 | 4.58 | 22.98 | 7.30 | 8.07 | Very Easy | 1 |
| 4 | 10.40 | 7.83 | 31.83 | 9.71 | 10.40 | Moderate | 3 |
| 5 | 8.87 | 10.56 | 40.3 | 10.95 | 13.66 | Difficult | 4 |
| 6 | 10.13 | 11.65 | 45.7 | 12.00 | 15.57 | Moderate | 3 |
| 7 | 9.08 | 12.01 | 39.72 | 10.25 | 16.41 | Very Easy | 1 |
| 8 | 7.92 | 8.20 | 44.33 | 11.37 | 11.52 | Very Easy | 1 |
| 9 | 3.05 | 1.41 | 14.25 | 6.54 | 4.06 | Very Easy | 1 |
| 10 | 12.16 | 14.28 | 45.46 | 12.34 | 19.11 | Moderate | 3 |
| 11 | 13.35 | 18.15 | 56.61 | 13.25 | 20.64 | Moderate | 3 |
| 12 | 9.57 | 11.98 | 42.13 | 11.12 | 16.60 | Moderate | 3 |
| Mean ± SD | 2.08 ± 1.16 |
To allow statistical comparison, the categorical outputs of ChatGPT were converted into numerical values: Very Easy = 1, Easy = 2, Moderate = 3, Difficult = 4, and Very Difficult = 5. Based on this transformation, ChatGPT’s readability classifications (n= 12) yielded a mean score of 2.17 with a standard deviation of approximately 1.00. This numeric representation enabled comparative statistical analysis alongside traditional readability metrics, thereby enhancing transparency and facilitating the calculation of central tendencies and variation.
The comparative analysis table presents five readability metrics results: Flesch-Kincaid (F-K), Automated Readability Index (ARI), LIX, SMOG, and Coleman-Liau Index (CLI) as well as ChatGPT's qualitative classification of text difficulty. It can be observed that F-K and ARI are highly correlated, with ARI generally producing slightly higher values. The LIX scores differ greatly, from 14.25 (Very Easy) to 56.61 (Difficult), which indicates that there is a large range of text complexity. The F-K and ARI rates are lower than SMOG and CLI rates. The ChatGPT’s classification is in good agreement with the lower F-K and ARI scores but is inconsistent for some moderate and difficult cases. For example, samples 1, 2, 3,and 9 have very low readability scores across all the metrics, which supports their “Very Easy” classification. However, samples 5, 6, and 12, which have high SMOG and CLI values, show a “Difficult” level, but ChatGPT only labels sample 5 as such, which may indicate that samples 6 and 12 are under-estimated. Anomalies are observed in sample 7, where despite the fact that CLI is 16.41 and LIX is 39.72, ChatGPT classifies it as “Very Easy” as opposed to “Moderate”. Likewise, samples 10 and 11 have the highest F-K (12.16, 13.35) and CLI (19.11, 20.64) and are labeled as “Moderate” rather than “Difficult” which is indicated by their numerical scores. In general, ChatGPT’s classification is in agreement with F-K and ARI, but tends to underestimate the difficulty when LIX, SMOG, and CLI suggest a higher level of text complexity. If the classification for samples 6, 7, 10, and 11 is adjusted to better reflect these metrics, then consistency and accuracy may be improved.
Table 8. Descriptive Analysis of Raw Scores
| F-K | ARI | LIX | SMOG | CLI |
| 12 | 12 | 12 | 12 | 12 |
| 7,9075 | 9,138333 | 36,50917 | 9,768333 | 12,65583 |
| 3,65933 | 4,860439 | 12,24386 | 2,55721 | 5,164377 |
| 3,05 | 1,41 | 14,25 | 5,93 | 4,06 |
| 3,72 | 5,18 | 29,6175 | 7,11 | 8,805 |
| 8,975 | 9,38 | 40,01 | 10,6 | 12,59 |
| 10,1975 | 11,9875 | 44,6125 | 11,5275 | 16,4575 |
| 13,35 | 18,15 | 56,61 | 13,25 | 20,64 |
Readability metrics analysis produces an extensive summary of text reading complexity. Most texts have a Flesch-Kincaid (F-K) score of 7.91 which corresponds to a reading level of 7th to 8th grade according to the median score of 8.98. The standard deviation of 3.66 shows that text difficulty levels vary moderately.
The Automated Readability Index (ARI) yields an average of 9.14, which aligns with a 9th-grade reading level, as indicated by its median score of 9.38. The standard deviation of 4.86 shows that this measure has a wider spread than F-K.
The LIX score exhibits the greatest degree of variability, with a mean of 36.51 and a standard deviation of 12.24. The range of 14.25 to 56.61 indicates that texts vary from very easy to fairly difficult, while the median value of 40.01 suggests that most texts fall into the moderate to slightly difficult category.
The SMOG index stands as the most reliable readability measure because it shows the lowest standard deviation, at 2.56, while its mean reaches 9.77. Most texts fall into the high school reading level category according to the median score of 10.60.
The Coleman-Liau Index (CLI) yields the most challenging results among the metrics, with a mean of 12.66 and a median of 12.59. Texts in this assessment extend from basic elementary material to advanced college-level complexity because the range spans from 4.06 to 20.64. The standard deviation of 5.16 indicates substantial text difficulty variations.
The positive skewness across all metrics indicates that more challenging texts tend to elevate the mean score. SMOG stands out as the most reliable metric among the three while LIX and CLI exhibit the greatest variability. The interquartile ranges demonstrate that most texts fall between middle school and early high school readability levels, but some outliers extend to both very easy and very difficult ends. The analysis reveals that the texts exhibit diverse levels of complexity, which tend to lean toward moderate to difficult readability.
Table 9. Correlations Between Raw Scores
| F-K | ARI | LIX | SMOG | CLI | |
| F-K | 1 | ,931822 | ,868049 | ,940019 | ,90785 |
| ARI | ,931822 | 1 | ,931668 | ,910844 | ,989241 |
| LIX | ,868049 | ,931668 | 1 | ,890237 | ,920522 |
| SMOG | ,940019 | ,910844 | ,890237 | 1 | ,894107 |
| CLI | ,90785 | ,989241 | ,920522 | ,894107 | 1 |
The correlation table demonstrates that allfive readabilitymetrics (F-K, ARI, LIX, SMOG, and CLI) exhibit strong positive relationships, as all values exceed 0.86, indicating their similar approach to assessing text difficulty. The correlation between ARI and CLI reaches its highest point at .989 which demonstrates their identical operational characteristics. The correlation between F-K and SMOG reaches .940 and F-K and ARI reaches .932 because these measures depend on sentence length and syllable count for their assessment. The correlation between LIX and SMOG reaches its lowest point at .890 because LIX evaluates readability through word length and density instead of syllable complexity. The ARI and CLI metrics show a near-identical correlation which indicates their redundancy in readability assessments. The results demonstrate that texts with similar ratings from one metric will receive comparable ratings from other metrics except for LIX which shows a slightly different pattern.
Prior to conducting correlation analysis, normality assumptions for thefive readabilitymetrics were tested using the Shapiro-Wilk test. The results indicated that none of the metrics significantly deviated from a normal distribution, with allp-values exceeding the .05 threshold (see Table X). Specifically, F-K (W= .888, p = .111), ARI (W= .976,p= .959), LIX (W= .950,p= .638), SMOG (W= .899,p= .154), and CLI (W= .972,p= .934) all met the assumption of normality. These results confirm the statistical suitability of using Pearson correlation coefficients in subsequent analyses.
Table 10. Shapiro-Wilk Test Results
| Readability Metric | W Statistic | p-value |
| F-K | .888 | .111 |
| ARI | .976 | .959 |
| LIX | .950 | .638 |
| SMOG | .899 | .154 |
| CLI | .972 | .934 |
Table 10 presents the results of the Shapiro-Wilk normality tests for each readability metric. All p-values exceed .05, indicating that the data do not significantly deviate from a normal distribution.
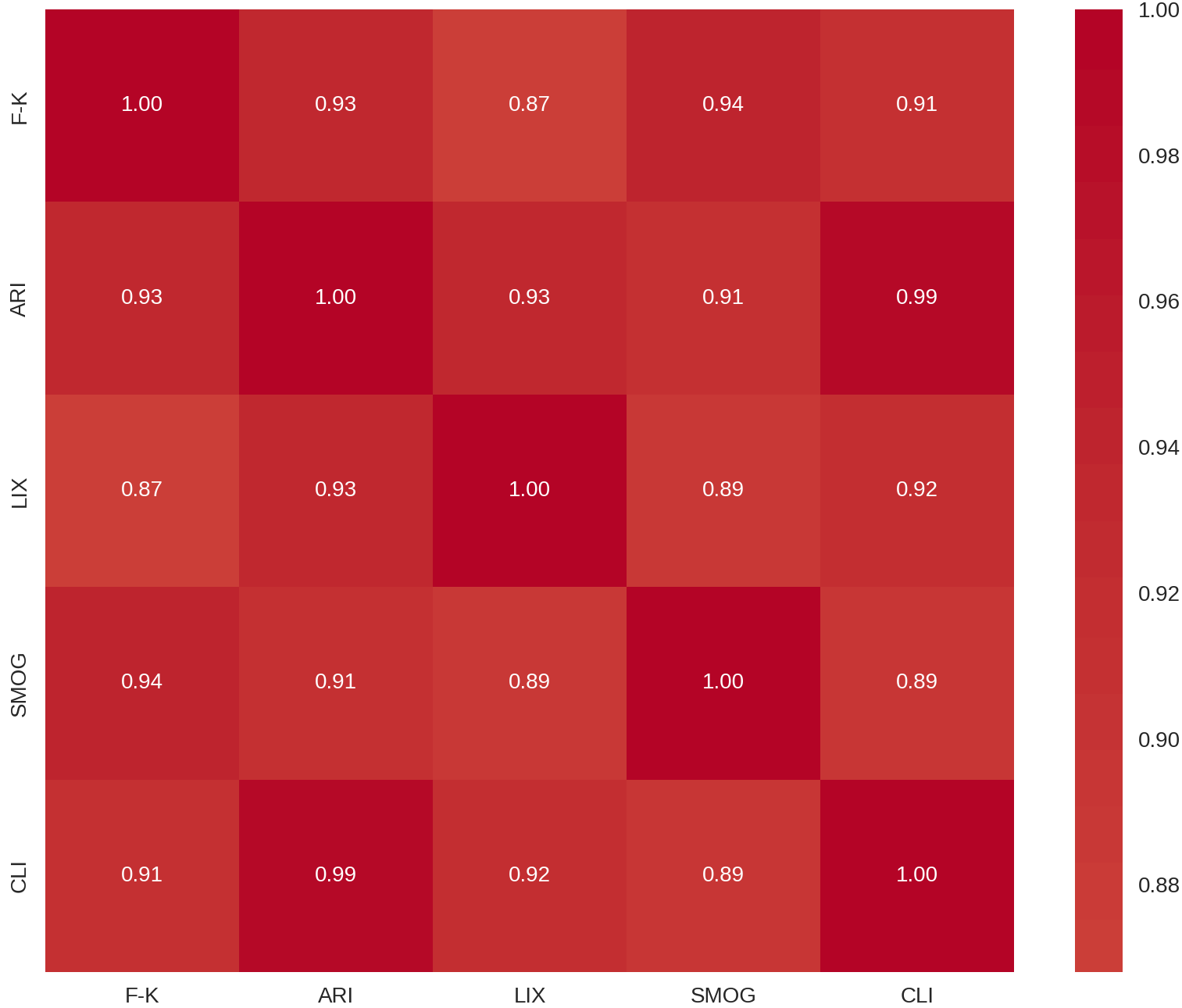
Figure 1. Correlation Heatmap of Readability Metrics
The figure displays the correlation heatmap of the five traditional readability metrics, showing pairwise Pearson correlation coefficients. The heatmap highlights the strong positive relationships between the metrics, illustrating their similar approach to assessing text complexity.
Table 11. Standard Errors
| 0 | |
| F-K | 1,0563574672 |
| ARI | 1,4030879545 |
| LIX | 3,5344984768 |
| SMOG | 0,738203012 |
| CLI | 1,4908272355 |
The standard errors for the readability metrics reflect the degree of variability in their estimations. SMOG shows the lowest standard error (0.738), indicating that it provides the most consistent and stable readability scores across samples. In contrast, LIX presents the highest standard error (3.534), likely due to its reliance on word length and lexical density, which can fluctuate widely across texts. The Flesch-Kincaid (1.056), ARI (1.403), and CLI (1.491) metrics fall within a moderate range, with ARI and CLI displaying slightly higher variability than Flesch-Kincaid. Notably, the correlation coefficients have zero standard error, confirming the high reliability of these estimates. Overall, the findings suggest that SMOG offers the most stable readability evaluations, whereas LIX tends to be more variable and sensitive to text-specific characteristics.
Table 12. 95% Confidence Intervals
| Mean | SE | 95% Cl Lower | 95% Cl Upper | |
| F-K | 7.9075 | 1.0564 | 5.8370 | 9.9780 |
| ARI | 9.1383 | 1.4031 | 6.3883 | 11.8884 |
| LIX | 36.5092 | 3.5345 | 29.5815 | 43.4368 |
| SMOG | 9.7683 | 0.7382 | 8.3215 | 11.2152 |
| CLI | 12.6558 | 1.4908 | 9.7338 | 15.5779 |
The 95% confidence intervals estimate the range in which the true mean readability scores are expected to fall, reflecting the variability in the data. For instance, the F-K metric has a corrected mean of 7.91, corresponding to a 7th to 8th-grade reading level, and aligns closely with the median score of 8.98. The other metrics also exhibit clearly defined intervals: ARI ranges from 6.39 to 11.89, LIX from 29.58 to 43.44, SMOG from 8.32 to 11.22, and CLI from 9.73 to 15.58. Among them, SMOG has the narrowest interval (2.89), reinforcing its stability as a readability measure with minimal variation. In contrast, LIX shows the widest interval (13.86), reflecting its greater standard error and variability. The overlapping intervals of ARI, CLI, and SMOG suggest that their scores are relatively consistent, whereas LIX results are more dispersed. Overall, the intervals indicate that the texts analyzed fall mostly within the moderate to difficult range in terms of readability.
Table 13. Correlations With GPT Assessments
| Correlation with GPT | |
| F-K | .75 |
| ARI | .65 |
| LIX | .57 |
| SMOG | .69 |
| CLI | .62 |
The matrix reveals a relationship between readability scores in GPT and traditional readability measures. The Flesch-Kincaid (F-K) score demonstrates the strongest relationship (r= .75) with GPT scores, showing the highest agreement in readability ratings from GPT. The strong relationship can perhaps be explained by F-K relying on sentence composition and syllable complexity—the two factors that have a notable impactonpeople's perceptions of text readability. Moderate correlations were found between GPT and SMOG (r=.69), ARI (r=.65), and CLI (r=.62), suggesting that GPT, to some extent captures the features measured by these tools, though not to the extent found in the case of F-K. The weakest correlation was found between GPT and LIX (r= .57), which may be due to the higher variability of LIX and its dependence on various attributes, such as word length and lexical density features that might be measured differently by GPT.
The results indicate that GPT's readability judgments are mostly influenced by F-K and SMOG, while showing the least alignment with LIX. The results indicate that GPT focuses on sentence structure and syllabic complexity instead of word length and lexical density, which are essential components of LIX.
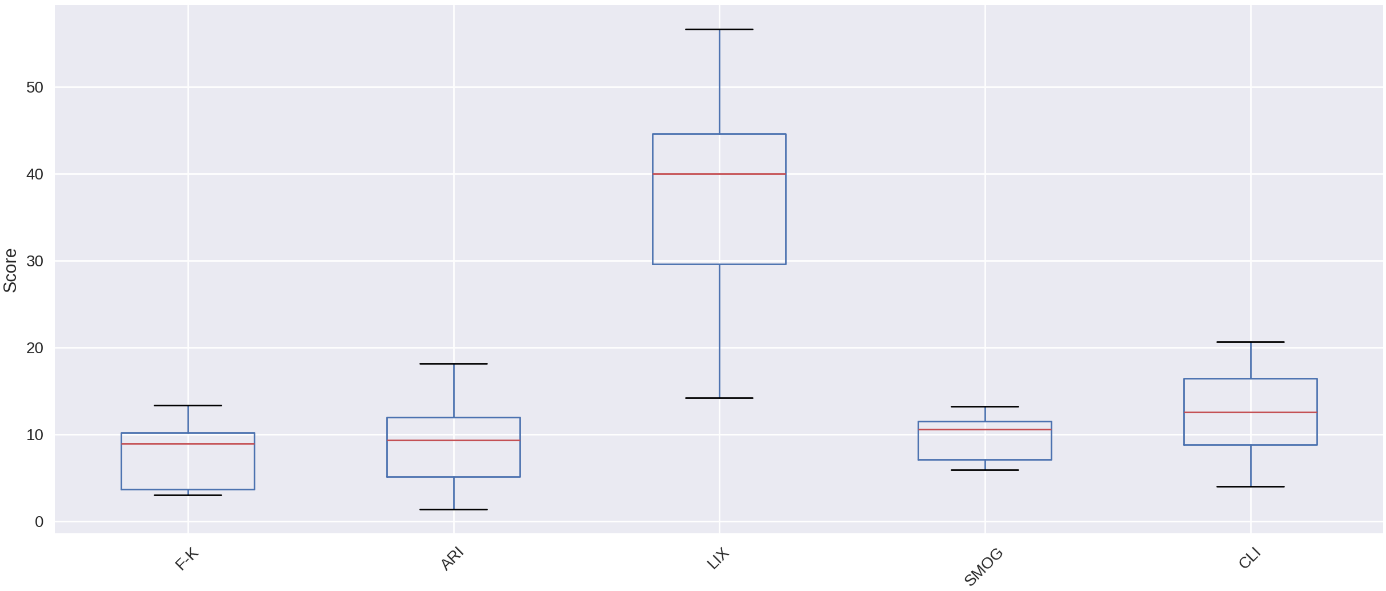
Figure 2. Distribution of Readability Scores Across Metrics
The statistical results showed significant correlation coefficient values. The introduction of AI-driven analysis tools such as ChatGPT through traditional methods brings new understanding to text readability analysis. The five readability metrics—Flesch-Kincaid (F-K), Automated Readability Index (ARI), LIX, SMOG, and Coleman-Liau Index (CLI)—along with ChatGPT’s qualitative classification of text difficulty. The results show that F-K and ARI have a strong correlation; however, ARI generates values that are higher than those of F-K. The LIX scores show a large range of values from 14.25 (Very Easy) to 56.61 (Difficult) which indicates diverse text complexities. The F-K and ARI ratings show lower difficulty levels than SMOG and CLI produce.
The classification system of ChatGPT shows good agreement with low F-K and ARI scores, but seems inconsistent for some moderate and difficult cases. For instance, samples 1, 2, 3, and 9 have very low readability scores for all metrics which supports their classification as “Very Easy”. However, samples 5, 6, and 12, which have high SMOG and CLI values, suggest a “Difficult” level, but ChatGPT only labels this as sample 5, which may indicate underestimation for samples 6 and 12. Sample 7 presents an anomaly because it has a high CLI (16.41) and LIX (39.72), but ChatGPT classifies it as “Very Easy” when a “Moderate” classification would have been more suitable. In the same way, samples 10 and 11 have the highest F-K (12.16, 13.35) and CLI (19.11, 20.64) but are labeled as “Moderate” instead of “Difficult” even though their numerical scores indicate high complexity. In general, ChatGPT’s classification is in agreement with F-K and ARI but tends to underestimate the difficulty when LIX, SMOG and CLI suggest higher text complexity.
The qualitative insights obtained from the feedback given by ChatGPT on text readability are particularly useful. ChatGPT was able to recognize features of language such as syntactic complexity, idiomatic expressions, and cultural references, which are usually not picked up by traditional metrics. This ability to capture deeper linguistic nuances highlights the potential of ChatGPT in supporting foreign language teaching and learning by providing insights that align with core competencies identified by language teachers, emphasizing the need for enhanced pedagogical skills in conjunction with AI.
The study results were validated through expert judgment to establish the reliability and validity of the findings. The alignment between ChatGPT's evaluations and traditional metrics assessments indicates that AI holds potential benefits for educational settings beyond traditional readability metrics.
The research demonstrates that AI tools, including ChatGPT, deliver more precise and context-specific readability assessments than standard measurement approaches. The research demonstrates how AI tools will transform readability evaluation by providing additional capabilities to traditional methods which leads to better educational materials.
Discussion
Implications of AI-Based Readability Assessment
The evaluation of readability demonstrates how ChatGPT AI tools measure text complexity in relation to established formulas. The results indicate some similarities in classification, but AI systems deliver additional understanding through contextual and semantic analysis which goes beyond traditional formula capabilities. The assessment results from AI tools differ from established tools because they do not match traditional measurement standards (Golan et al., 2024). The development of AI writing capabilities to mimic human writing continues to progress, but it still produces different linguistic features which impact readability evaluation (Devitska& Horvat-Choblya, 2024). The educational application of ChatGPT and similar AI tools demonstrates potential by making complex texts easier to understand especially when working with non-English languages where they have achieved substantial readability score improvements (Sudharshan et al., 2024). The quality and reliability of AI-generated content need further development because AI systems occasionally produce assessments that differ from human evaluators' judgments about quality and readability (Golan et al., 2024; Ömür Arça et al., 2024).
The research demonstrates both the educational benefits of AI technology and the requirement to handle its boundaries while implementing it properly. AI tools offer new methods to analyze text complexity yet their combination with traditional readability assessments needs ongoing evaluation for maintaining accuracy and fairness and educational worth (Golan et al., 2024; Gondode et al., 2024; Sudharshan et al., 2024).
Limitations of ChatGPT’s Approach
ChatGPT's approach has several limitations that need to be taken seriously in pedagogical contexts. First is the "black box" nature of the system that does not offer any clear insight into its inner reasoning mechanisms. This makes it impossible for instructors and researchers to monitor how linguistic features—such as syntactic complexity and lexical density—influence the model's readability choices. Also, the model is not precisely designed for the CEFR foreign language levels and does not have the capacity to differentiate between essential factors in foreign language learning, e.g., high-frequency words vs. low-frequency words.
A further major limitation is the sensitivity of ChatGPT to prompt wording, affecting reproducibility and standardization. The literature suggests that minor changes in prompt wording can substantially alter the model's output and accuracy.
For instance, in testing educational software, ChatGPT responded correctly or partially correctly 55.6% of the time, which was enhanced slightly when context for questions was given (Newton &Xiromeriti, 2024). Similarly, its performance varied by subject area across UK standardized entry examinations, with strengths in reading comprehension, while scores were poorer in maths, pointing to the model's reliability being domain-dependent (Newton &Xiromeriti, 2024).
Additionally, there have been issues raised regarding ChatGPT use in universities, with a focus on academic integrity and the abuse of AI to avoid learning (Consuegra‐Fernández et al., 2024;Welskop, 2023). One of the challenges is how it becomes almost impossible to tell whether text was written by humans or by AI since teachers have shown low accuracy levels when detecting AI-written essays (An et al., 2023). Although prompt engineering has the potential to improve the quality of output from ChatGPT, several concerns remain, such as the generation of incorrect information, the potential to bypass plagiarism detection tools, and algorithmic biases capable of distorting the content (Adel et al., 2024; Lo, 2023). Such findings highlight the need for rigorous assessment methods, organizational guidelines, and ethical standards to ensure the responsible and effective integration of artificial intelligence in the educational sector (Adel et al., 2024).
Practical Implications for Educators
In spite of its limitations, ChatGPT has tremendous potential as an ancillary tool in text modification and selection tasks. Teachers can use it for instant text appraisals of suitability for A1 or B1 learners and even seek feedback for student-authored exercises. Classroom exercises can include comparing ChatGPT's appraisals with traditional teaching methods or editing texts as per its recommendations. As part of teacher training programs, ChatGPT can assist in developing prompts, exploring limits in AI capabilities, and analyzing recommendations by AI. To ensure effective integration, educators should formalize AI use through clear prompts aligned with pedagogical goals and map AI feedback to CEFR descriptors. Regular calibration sessions—comparing teacher and AI evaluations—can build trust and optimize classroom use. Institutions should also provide workshops to share best practices and address AI-related challenges. Embedding AI tools in Learning Management Systems offers seamless lesson planning with immediate feedback.
Specifically regarding ChatGPT, educators can use open-source alternatives like LM Studio in order to enable offline use and ensure privacy. When applied sparingly and as part of pedagogy expertise, AI tools can enhance teaching but must not replace professional judgment. Beyond education, ChatGPT has shown versatility across fields. In healthcare, it adapts communication for patients and professionals but cannot replace expert judgment (Kaarreet al., 2023;Liet al., 2023). In academic writing, it aids in drafting and organization but raises concerns over accuracy and source reliability (Akpur, 2024;Livberber, 2023). Applications in programming, geography, and material science demonstrate potential for personalized learning, though challenges like bias, inaccuracies, and ethical issues persist (Bringula, 2024; Chowdhury & Haque, 2023; Deb et al., 2024; X.-H.Nguyen et al., 2023). While ChatGPT’s conversational abilities are impressive, its limitations require careful management. As AI evolves, more advanced and reliable models are expected (Cheng, 2023; Hariri, 2023).
To enhance the effectiveness of AI-based readability assessments, future research should focus on optimizing outputs to better align with human assessments and levels within the Common European Framework of Reference (CEFR). The CEFR offers a systematic framework for language proficiency assessment, and its adoption can improve the assessment of text difficulty (Arase et al., 2022). Current studies highlight challenges in extrapolating models to diverse text types and languages, thus underscoring the need for a wider range of training data (Ribeiro et al., 2024). Multilingual and multi-domain datasets like ReadMe++ have been shown to have the potential to improve cross-lingual transfer(Naouset al., 2023). Furthermore, BERT-based models using feature projection and length-balanced loss have achieved almost human-level performance (Li et al., 2022). In European Portuguese, models carefully calibrated achieved around 80% accuracy but struggled when applied in different genres (Ribeiro et al., 2024). Comparatively, in the case of French,studies explored interactions between mechanisms involving attention, linguistic features, and CEFR predictions (Wilkens et al., 2024). Redefining readability as a regression task improved accuracy and generalization (Ribeiro et al., 2024).
Instruction-tuned models like BLOOMZ and FlanT5 outperformed ChatGPT in readability-controlled tasks, highlighting the need for refined prompts and tuning (Imperial &Madabushi, 2023). However, human variability in using GPT-4 for readability manipulation reveals ongoing refinement needs (Trott & Rivière, 2024).
In summary, advancing AI readability tools requires expanding multilingual datasets, enhancing cross-domain generalization, and fine-tuning outputs to align closely with CEFR and human standards.
Conclusion
The evaluation of text readability through traditional methods shows strong agreement with AI-based classification but produces some inconsistent results. The F-K and ARI metrics match ChatGPT's ratings closely but LIX and SMOG and CLI tend to rate texts as more challenging. The correlation analysis shows that readability metrics share similar patterns but LIX produces a different pattern because it focuses on word length and lexical density. The research shows that AI readability assessments work well but tend to miss the level of difficulty when texts contain complex structures. The accuracy of AI models would increase if developers added more advanced linguistic elements, such as sentence structure and lexical variation,to their systems. SMOG demonstrates the highest reliability among the metrics while LIX produces the most variable results. Future studies should investigate how combining human evaluation with AI-based models would improve readability scoring precision. The observed differences in classification demonstrate that using AI-driven assessments together with traditional formulas could create a more balanced readability evaluation system.
Recommendations
The study presents key research recommendations for teaching and investigation methods about AI readability assessment. The implementation of ChatGPT, along with other AI tools within educational settings, particularly foreign language instruction,shows promise yet demands careful strategic execution to achieve meaningful results.
Educators, together with textbook authors and curriculum developers, need to combine traditional readability formula assessments with artificial intelligence model insights in their evaluation methods. The study demonstrates that Flesch-Kincaid and SMOG and LIX provide solid bases for determining text difficulty by analyzing sentence length and word forms. These approaches fail to detect essential linguistic, semantic, and cultural elements that significantly impact comprehension, especially for students learning foreign languages. The AI system ChatGPT successfully identified some minor details, such as regular expressions, discursive coherence, and syntactic transformation, which frequently determine text readability for various student skill groups.
AI evaluations should be viewed as supplementary tools which provide additional study perspectives instead of replacing current methods. The combination of standard methods with AI analysis enhances text rating precision ,particularly in multilingual and multicultural educational environments. The evaluation and selection or modification of teaching materials in German as a Foreign Language (GFL) courses should utilize AI alongside standard measurement tools, according to educators and researchers. The implementation of AI knowledge as a core component should be integrated into teacher professional development and career advancement programs. AI models, including readability orders and language feedback,require teachers to develop abilities for assessing their outputs. Teachers need professional development which covers tool proficiency along with boundary understanding and prompt design significance. Educators would then be able to evaluate AI feedback effectively while developing data-driven and considerate teaching practices. The development of specific prompts and readability evaluation models is necessary to meet the requirements of language learning assessments. Standard prompts were used with ChatGPT,but the model produced mostly equivalent yet occasionally incorrect responses when evaluating medium and hard text orders. The results indicate that modifying prompts to match language student requirements by integrating CEFR level words and grammar signs might boost the reliability of AI evaluations. Organizations, together with publishers, should explore the development of location-specific models trained on educational materials to enhance accuracy while maintaining meaningful results.
Learning people should conduct backtesting of plans and work that implement AI tools such as ChatGPT in actual classroom environments at both group and policy stages. The plans would evaluate how AI feedback measures up against student understanding and their perceptions of difficulty compared to teacher skill assessments. The implementation of these acts would reveal optimal methods while revealing deficiencies to achieve equitable and beneficial AI usage in learning assessment. Future studies should evaluate cross-language value by determining the applicability of AI readability evaluations across multiple languages and student populations. The change in syntactic and word difficulty across languages requires additional research because the current work focused on German-language books. The ability to analyze text difficulty through AI models in various languages, such as Turkish, Japanese, and Arabic, would extend the scope of results and develop open learning practices. AI learning evaluation requires a strong emphasis on both educational ethics and teaching requirements. Readability extends beyond numerical or computational values because it directly relates to students' backgrounds and motivations, as well as their cultural backgrounds and educational objectives. Readability tools exist to assist teaching professionals rather than replace their evaluation capabilities. Teachers must retain their central role in determining appropriate materials for their students, while AI suggestions should serve as one of several educational resources in the overall teaching process. The readability evaluation benefits from ChatGPT and similar AI tools, which provide a valuable but evolving assessment capability. Foreign language learning will advance toward more suitable student-centered approaches through combined human and machine intelligence collaboration.
Limitations
The research focuses on a limited number of German foreign language textbooks together with one AI model named ChatGPT. The results obtained in this study may not apply to different languages, AI systems, or various writing styles. The AI assessments depended on the question formats used. The evaluations of ChatGPT lacked human input from language learners and instructors,even though they occurred in real time. The training of ChatGPT did not include any special evaluation of reading ease. The frequency of text categorization may be affected by the regularity of the process, especially when dealing with difficult texts.
Ethics Statements
The research project did not have human participants or private information. It did not need permission from an ethics committee. All of the textbook sections were open for anyone to view or were authorized course materials. The artificial intelligence was employed in a proper way. The methods and review were clear. Steps were taken not to wrongly depict what the system can achieve. Steps also existed to make sure the comparative studies were correct and just.
The authors presented an initial version of this research at the 9th International Conference on the Future of Teaching and Education,which took place in Vienna during March 2025. The authors received useful feedback at the conference, which they used to enhance and finalize the research paper. The author gratefully acknowledges the valuable comments and constructive suggestions of the anonymous reviewers, which have substantially improved the quality and precision of this work.
Conflict of Interest
The author declares no conflict of interest. There are no financial, personal, or professional affiliations that could be perceived as influencing the research.
Funding
This research was funded by the Scientific Research Coordination Unit of Anadolu University under project number SÇB-2024-2587. The funding institution had no role in study design, data collection, analysis, or publication decisions.
Generative AI Statement
As the author of this work, Generative AI (ChatGPT, GPT-4) was used exclusively to assess the readability of selected textbook texts, based on predefined prompts. Its role was limited to generating readability classifications, which were then compared with traditional metrics. After using this AI tool, I reviewed and verified the final version of my work. I, as the author, take full responsibility for the content of our published work.