
Introduction
ChatGPT or artificial intelligence (AI) in general has gained significant attention from educators(Liang et al., 2023) and is believed to have the potential to shift educational goals towards the highest cognitive levels(Hwang & Chen, 2023).ChatGPT showcases impressive capability and user interaction, sparking investigations into its use as a tool for thinking in education, stimulating cognition, reflection, and understanding of complex concepts(OpenAI, 2023). Currently, ChatGPT is a central topic of discussion in education across various disciplines and levels(Polverini&Gregorcic, 2024a).
Since AI technology plays a significant role in learners' lives, educational institutions are urged to integrate it into educational processes for productive use(Chinonso et al., 2023).This integration remains a vital topic of discussion and research. Furthermore, if educators meaningfully incorporate this technology into educational processes, it is essential that they stay up to date on its rapid advancements, including studies on its capabilities, consistency, strengths, limitations, and potential biases.
Research on ChatGPT's capability has been conducted through conversations between researchers and ChatGPT (Gregorcic & Pendrill, 2023). The use of ChatGPT in education to enhance critical thinking skills at the secondary school level provides easily implementable examples of how ChatGPT can be utilized in classrooms (Bitzenbauer, 2023). Initial tests of ChatGPT's capabilities demonstrate its accuracy in completing complex tasks, with performance nearly on par with that of humans. However, its performance in mathematics has been shown to lag significantly behind experts and m { REF _Ref187868631 \r \h \* MERGEFORMAT } ay still fail in some basic mathematical reasoning tasks unless supplemented with external plugins (Bubeck et al., 2023).
The physics education research community has also explored ChatGPT's performance across various tasks. For instance, ChatGPT-3.5's responses to simple mechanics problems revealed incorrect and contradictory physical reasoning(Gregorcic&Pendrill, 2023).Based on that research, the same problems were posed to several AI models, and it was found that ChatGPT-4 outperformed Bing Chatbot, Bard, and ChatGPT-3.5(dos Santos, 2023). However, a review of ChatGPT-4's performance on multiple-choice exams concluded that it demonstrated only moderate proficiency in problem-solving, transfer tasks, and mathematical problems (Newton & Xiromeriti, 2023) . Testing results indicated that ChatGPT possesses critical thinking skills, the ability to handle simple logical problems, and a tendency to perform well on tests of problem-solving, collaboration, communication, and metacognition(Yanget al., 2023).
In addition to focusing on AI performance across various task types and standardized assessments, previous studies have also analyzed AI performance using multiple-choice tests(Newton &Xiromeriti, 2023;Polverini&Gregorcic, 2024b). However, based on extensive searches conducted, no research to date has examined the capabilities and consistency of AI, including ChatGPT and Gemini, using multiple-choice tests in a two-tier format. This study aims to narrow that gap. The research results will contribute to building a database of AI's strengths and weaknesses and will serve as part of the training and enrichment process to improve AI's capability across various task formats. The two-tier multiple-choice test includes Tier-1, the main question requiring respondents to select the correct option, and Tier-2, which asks respondents to explain the reasoning behind their Tier-1 choice. Capability and scientific consistency can be assessed through tests in this format. The responses of these two AI models can also be compared with those of students, allowing their levels of capability and consistency to be evaluated.
Recent educational research on AI-powered tools, such as ChatGPT, has primarily examined their roles in assessment and learning contexts.Kortemeyer(2023) examined how ChatGPT tackled the Force Concept Inventory (FCI), homework assignments, programming exercises, and exam questions, while Kieser et al. (2023) analyzed ChatGPT’s accuracy in solving FCI and modelled its performance as that of students from various groups. On the other hand, Liang et al. (2023) explored the pedagogical benefits of ChatGPT in physics, revealing that this AI could answer questions, provide explanations, and generate new exercises comparable to those created by humans. Alarbi et et al. (2024) investigated the impact of ChatGPT on the learning outcomes and academic performance of high school students in topics such as Newton’s second law. Al Ghazali et al. (2024) explored ChatGPT’s potential as a teacher replacement but highlighted the need to address biases and limitations, as outlined by Bitzenbauer (2023).Halaweh(2023) provided an in-depth examination of the concerns and potential of ChatGPT’s use in educational contexts.
In addition to ChatGPT, Google Gemini (Gemini) stands out for its ability to deliver factual information due to its integration with Google Search. According to Google’s report, Gemini differs from ChatGPT by accurately recognizing all handwritten content and verifying reasoning in evaluating student solutions to physics problems (Anilet al., 2023). Research on Gemini has been conducted by various scholars, such as studies comparing human and AI understanding of the nature of science (Nyaaba, 2023) and the comparative performance and capabilities of ChatGPT and Gemini (Rane et al., 2024). Jere (2025) evaluated three AIs (ChatGPT Plus’s, Gemini’s, and Claude 3.5 Sonnet’s performances in a high school chemistry exam. Another study (Perera &Lankathilake, 2023) explored diverse perspectives on the future of ChatGPT and Geminiand offeredcomprehensive recommendations for education and research. These previous studies offer valuable insights into the roles of ChatGPT and Gemini in education, highlighting the need for further research and exploration in this field. ChatGPT and Gemini represent two leading advancements in natural language processing and conversational AI (Fu et al., 2023; Kandpalet al., 2023). Both models leverage sophisticated architectures to enhance their conversational capabilities and knowledge synthesis (Rane et al., 2024).
Research on the applications of ChatGPT and Gemini in education is extensive; however, no studies have yet compared the capabilities and scientific consistency of these two AI systems. ChatGPT’s and Gemini’s capabilities can be analyzed through tests in different formats. In this regard, an online two-tier test consisting of 25 items on the basic concepts of static fluid has been developed(Kaharuet al., 2024). This test was built upon previous research (Kaharu&Mansyur, 2021) and has been applied in subsequent studies (Mansyur et al., 2022a,2022b). The test design includes Tier-2 as the reasoning behind the Tier-1 choices, supporting an in-depth examination of the thinking behaviour and consistency of AI, students, and pre-service teachers.
Science education research has studied learners’ thinking behaviour, such as their understanding of floating and sinking phenomena in fluid (Minogue & Borland, 2016). In the context of buoyant objects, previous studies have highlighted unique learner thought patterns. For instance, statements like “an object that is suspending but nearly submerged” for stable objects near the liquid’s surface or “a suspending object with a density greater than the liquid” for objects stable near the bottom of a container illustrate such peculiarities(Mansyur et al., 2022a, 2022b). The factors underlying these thought patterns require further exploration to uncover the conceptual aspects that influence them.
In the context of static fluid,Kaharuand Mansyur(2021) developed an essay test to explore students’ mental models and representational patterns. This research was later extended by Kaharuet al.(2024), resulting in the development of an online two-tier test on static fluid (2TtSF). The test consists of Tier-1, where respondents select answers based on static fluid phenomena, and Tier-2, where they provide reasons or justifications for their answers. The goal of this test is to evaluate respondents’ abilities to reason logically and construct arguments.
While many studies have assessed ChatGPT’s performance, none have specifically tested its ability to complete two-tier tests such as 2TtSF, particularly the capability and scientific consistency in the context of static fluid. This study aims to evaluate ChatGPT’s and Gemini’s capability and scientific consistency in responding to the 2TtSF test and to compare their results with the performance of students and pre-service teachers. The study provides empirical data on the strength, potential, and limitation of strengths, potential, and limitations of ChatGPT and Gemini in supporting education. Additionally, the application of the two-tier test and Socratic dialogue during the study is expected to enrich the knowledge base of ChatGPT and Gemini, enhancing their capability as more effective learning tools.
Expanding the understanding of ChatGPT’s and Gemini’s potential in education requires an assessment of their capability and consistency across various task formats. To this end, the framework positions AI as a learner, testing its ability and comparing them to that human learners (Vasconcelos & dos Santos, 2023). AI is used to generate synthetic response data (Kieser et al., 2023) and to examine its engagement in Socratic dialogue (Gregorcic&Pendrill, 2023). In this context, AI is attributed human-like traits and behaviours, assuming the chatbot possesses thinking abilities. Under this assumption, the capability and scientific consistency of AI can be compared to those of students and pre-service teachers when responding to the two-tier test format.This research is expected to narrow the existing gap concerning the absence of previous research that explored the capability and scientific consistency of the two AIs and students. Therefore, this research aimed to empirically compare the capability and scientific consistency of ChatGPT, Gemini, and students in responding to a two-tier test format of static fluid concepts. Based on the identified gap, the research is guided by the following questions:
To what extent do ChatGPT and Gemini demonstrate capability and scientific consistency in responding to two-tier static fluid compared to human learners?
What types of reasoning and consistency patterns characterize ChatGPT’s and Gemini’s responses across similar conceptual contexts in static fluid phenomena?
Literature Review
AI has grown beyond a tool to help augment people, and now becomes a cognitive partner that can trigger reasoning, reflection, and concept understanding in educational situations. Systems, such as ChatGPT and Gemini, support learners to reason and dialogue about ideas in such a way that they do not retrieve information but construct meaning (Hwang & Chen, 2023; Liang et al., 2023). In AI, with the increased involvement of AI in educational systems, the research focus has moved towards exploring not just how AI can be used as a medium to teach but also as a cognitive model that can mimic human-like reasoning and problem-solving behaviour.
Among generative AI models, ChatGPT has attracted a lot of attention because of its linguistic fluency and analytical capacity. Research demonstrates that ChatGPT can generate coherent explanations and detailed conceptual connections, whereas its reasoning ability in physics and mathematics sometimes exhibits inaccuracies or inconsistencies (Gregorcic&Pendrill, 2023; Newton &Xiromeriti, 2023). These discrepancies are inherent to the probabilistic composition of LLMs, which prioritize textual coherence over empirical truth. As a result, though ChatGPT’s answers might seem scientifically erudite, they are usually not based on context – evidence that its process is a syntactical one rather than experiential.
Google’s Gemini, by contrast, uses multimodal data processing and supports real-time search for text, images, and fact retrieval (Anieto et al., 2023). This structure offers Gemini the capability to work with information that is reliant on proof orafactual basis. But there are a few literature reports on the extent of its reasoning consistency. It is therefore desirable to compare ChatGPT and Gemini to shed light on how their respective architectures influence cognitive stability and scientific reasoning. Both models prove feasible as reasoning partners but show limitations on domain-specific scientific concepts (e.g. static fluid).
Two intertwined concepts, i.e., capability and scientific consistency,are set as two major indicators while we evaluate the performance of reasoning. Capability reflects the production of correct responses, and scientific consistency indicates reasoning that is consistent across similar conceptual contexts (Nieminen et al., 2010). Learners or AI models may demonstrate high capacity yet low fidelity, a reflection of shallow understanding or context-dependent reasoning. This dual framework is a key to separating understanding-based accuracy from pattern- or memorization-based correctness.
The two-tier diagnostic test is a widely utilized tool for not only assessing conceptual understanding, but also coherence of reasoning (Caleon& Subramaniam,2010a; Chu et al., 2009).Tier-1 considers correctness, Tier-2 is concerned with justification. This architecture allows for both false positives and accurate responses with wrong justification, and negative false responses as incorrect responses with scientifically plausible cardinals (Bayrak, 2013). These differences provide an indication of the extent of understanding, thus providing a way for researchers to measure reasoning quality beyond mere surface-level correctness.
In physics education, two-tier tests have been particularly successful in revealing concepts related to abstract or intuitive questions. For example, Kaharuet al. (2024) have developed an online two-tier test on static fluid, which represents an advancement of this approach by providing an interactive format that enables detailed observation of cognitive patterns..Static fluid ideas (e.g., buoyancy, density, and equilibrium), which typically provoke some intuitive but incorrect reasoning from students, arehighly appropriate for diagnostic work (Minogue & Borland, 2016). This domain, therefore, provides a context for testing both human and AI reasoning consistency.
The pattern of false-positive and false-negative responsesshedsadditional light on the mental calculations operated by AI models, as well as by human learners. False-positive, which is a frequent term for students, indicates the presence of hidden misconceptions behind the correct answer, whereas false-negative can be associated with AI or learners that demonstrate progress in generating hypothetical reasoning due to partial compliance with scientific reasoning (Aldazharova et al., 2024). So, if humans trust perception-based intuition, it seems that AI ends up trusting more linguistic coherence and produces sound chains of reasoning, which may lead us to wrong conclusions.
The idea of scientific consistency generalizes this analysis by focusing on coherence across distinct but related activities. A consistent answerer exhibits coherence while responding to several related questions having common underlying principles (Nieminen et al., 2010). Inconsistencies, though, suggest fragmented conceptual frameworks, whether these are due to humans' having incomplete knowledge or to AI's skewed data-based biases. Utilizing such a paradigm for ChatGPT and Gemini lets researchers investigate whether language models exhibit consistent conceptual reasoning or instead vary from context to context (given prompt design).
Socratic dialogue has been proven to be an effective way to drive a deeper level of reasoning for AI systems. Through asking structured questions, researchers can challenge AI to clarify its explanations and display evidence of self-correction (Bitzenbauer, 2023;Gregorcic & Pendrill, 2023). This dialogic perspective makes AI more than a computing machine but a “thinking partner” that can emulate metacognitive reflection. While such an explanation is still linguistic and not experiential, it gives us insights about how AI models extract feedback and achieve coherence in conceptual domains like physics.
Recent research exploring AI performance in education has not systematically compared the ability and external reliability of several AI systems to apply a diagnostic two-tier test. Prior work has primarily focused on the output correctness instead of reasoning coherence. This is the issue that this paper seeks to address by exploring ChatGPT and Gemini as proxies for learners whose reasoning can be investigated empirically. By comparing the quality of their responses to static fluid problems, we will seek to provide some understanding of how generative AI systems are able to demonstrate conceptual and scientific coherence, which serves as a groundwork for their pedagogical integration.
Methodology
Research Design
This study employed a comparative, quantitative-descriptive design with a convergent parallel strategy. Quantitative analyses were used to assess the capability and scientific consistency of both AI systems and student participants, while descriptive analyses examined some examples of AI-generated responses. Integration occurred through a joint display linking statistical outcomes with descriptive analysis. For example, higher quantitative scores were compared with coherent reasoning patterns, while lower scores were associated with recurring qualitative descriptions.
Subject and Participant
The primary subjects of this study are ChatGPT-4o (released on May 13, 2024) and Gemini 1.5 Pro-001 (released on May 24, 2024). The inclusion of junior high school students, senior high school students, first- to fourth-year pre-service elementary school teacher students, and professional program students in elementary school teacher education aims to determine the level of AI capability and consistency compared to those of students. A description of the study subjects and participants is presented in Table 1.
Table 1. Description of the Research Subjects and Participants
| Subject | Group | Number | Group Code | Remark |
| ChatGPT | ChatGPT-4o | 60 | GPT | One item was completed (60 times separately for 25 pair items., total 60 x 25 = 1.500 prompt pairs) |
| Gemini Google | Gemini 1.5 Pro | 60 | Gem | One item was completed (60 times separately for 25 pair items., total 60 x 25 = 1.500 prompt pairs) |
| 8th | 60 | JH8 | 2 schools | |
| High school student | 9th | 60 | JH9 | 2 schools |
| 11th | 69 | SH11 | 2 schools | |
| 12th | 60 | SH12 | 2 schools | |
| University student | 1st year | 74 | ET1 | Elementary school teacher education |
| 2nd year | 67 | ET2 | Elementary school teacher education | |
| 3rd year | 60 | ET3 | Elementary school teacher education | |
| 4th year | 59 | ET4 | Elementary school teacher education | |
| Professional program | 51 | PP | Elementary school teacher professional program | |
| Number of participants | 680 |
School student participants were selected from two top-performing schools in the city where the research was conducted, at the junior and senior high school levels. Meanwhile, university student participants were determined based on their cohort of enrollment. Although there was no informed consent for the students, their participation was voluntary after the research team obtained official permission from the schools and the university to conduct the study. There were no criteria regarding the proportion of participants based on gender or socioeconomic background.
All test participants were assumed to have previously learned the basic concepts of static fluids, particularly floating, suspending, and sinking. This assumption was applied because these concepts have been taught since the elementary school level.
Instrument
The research instruments consist of: (1) ChatGPT and Gemini accounts, which act as tools for responding to the two-tier test and simultaneously serve as subjects; (2) A online two-tier test package, developed using the Jotform.com application and refined in previous research (Kaharuet al., 2024); and (3) A prompt guide package for ChatGPT and Gemini.
The test has an item reliability of .94 (very high) based on Rasch analysis (Winstep), and content and construct validity were in the very good category (Kaharuet al., 2024). The developed test covers various contexts and concepts in static fluids,including the representation of floating, suspended, and sinking objects; the influence of density, shape, and size; the effects of hollows and holes; and other interconnected factors. The concepts are included in science topics in elementary students (grades 5 to 6), junior, and senior high school. The topics are also a part of the material learning of the Basic Concept of Science course in the elementary school teacher preparation program at Tadulako University. These allow for an in-depth exploration of scientific consistency using the test.The test package can be accessed by submitting a request to the authors. The prompt guide for ChatGPT and Gemini has undergone expert validation. The validation process for the prompt guidelines involved two experts in the field of artificial intelligence,as well as subject-matter experts in physics.
Table 2. The Grouping of Test Items Based on the Aspects Explored
| Group | Description | Item Number |
| A | Diagrams of objects in fluid | 1, 2, 3, 4 |
| B | Diagrams of suspending objects in fluid in relation to density. | 5, 10, 11, 12, 13, 23 |
| C | Properties of objects in a fluid based on certain treatments | 6, 7, 8, 9, 14, 15, 16, 17, 18 |
| D | Representations of objects when modified | 19, 20, 21, 22 |
| E | Properties of objects in a fluid related to some factors | 24, 25 |
Items within the same group belong to the same concept, differing only in context. The concept concerns the impact of creating holes or hollows in the properties or representations of objects. The context that differentiates them involves whether the object is floating, suspended, or sinking. Another variation includes hollow objects with objects floating, suspended, or sinking in air or water, and the effects on their properties or conditions in the fluid. For example, items from Group C (10 items) were provided and considered within the same group, allowing for the measurement of scientific consistency by examining the subjects' average scores for the group. Subjects at Level I, Level II, and Level III reflect their level of scientific consistency. The higher the proportion of subjects at Level I, the greater the scientific consistency of subjects within the group of items. Conversely, a higher proportion of subjects at Level III indicates a lower level of scientific consistency.
Data Collection
Data collection employed the following approaches:
a. Providing Instructions (prompts) to ChatGPT and Gemini. The simple and generally applicable prompt format is illustrated through the following example: For Item Number 1, in Tier-1 ,the AI is asked to choose the option it considers correct without providing any explanation for its choice. After the AI presented their answers, the researcher proceeded directly to Tier-2 (not as a new chat), where the AI is asked to select an option relevant to its Tier-1 choice and provide a brief explanation. This process was then repeated for Items No. 2 through No. 25. In this procedure, each AI is considered to represent one respondent completing a single set of the two-tier test. The same process is then repeated for the second respondent up to the sixtieth respondent. All sessions started as a new chat to avoid carryover effects between the sessions and allow for independent data collection. The format of the system prompt and instructional screen was identical across all sessions. Both AIs were running the same temperature parameter (which was set to 0 for no randomness and deterministic outputs). The format of the stimuli was consistent throughout and the order in which items were presented was randomized for each new session to prevent pattern analysis or context effects. These steps were included to achieve independence of responses from each AI, and to allow the total sequence to be repeated could be replicated under the same conditions. To reduce potential bias related to the timing of the AI prompting by considering that AI systems may evolve over time through continuous updates or “learning” processes, the prompting procedure involved ten persons working in parallel, allowing all sessions to be completed within two days.
b. Conducting confirmatory dialogue (Socratic dialogue) with ChatGPT and Gemini separately for unique responses on the two-tier test (e.g., inconsistent answers or other responses requiring clarification).
c. Online testing for students. Students completed the test online while being physically present in the classroom.
Analyzing Data
Data analysis encompassed aspects of capability and scientific consistency. Capability was measured based on scores obtained from the two-tier test. Scoring of the test results followed the rubric presented in Table 3, as adapted from Chang et al. (2007), Chu et al. (2009), and Bayrak (2013).
Table 3. Scoring rubric for capability assessment
| Category | Description | Score |
| Individual item | correct = 1, incorrect = 0 | 1/0 |
| Combined items | two correct = 2, one correct = 1, both incorrect = 0 | 2/1/0 |
| Paired items | two correct = 1, one or both incorrect = 0 | 1/0 |
For example, in Item No. 1, if both Tier-1 and Tier-2 answers are correct, the respondent receives a score of 1 for the individual item, a score of 2 for the combined item, and a score of 1 for the paired item. If the respondent answers correctly in only one of the tiers, they receive a score of 1 for the individual item, 1 for the combined score, and 0 for the paired score. The respondent receives a score of 0 in all categories if both Tier-1 and Tier-2 answers are incorrect.
The capabilities of ChatGPT and Gemini were compared both quantitatively and descriptively with those of the students. The comparison was conducted using ANOVA and subsequent Tukey tests atp< .05 was analysed with licensed SPSS Statistics 27.0 (IBM Corp., 2024). Based onthe number of respondents for each category and sampling technique, we made assumptions on the distribution, homogeneity, and variance of thepopulation to implement parametric analyses.When the assumption of homogeneity is not met, Welch ANOVA and the Games-Howell post hoc test are used (Lakens, 2013). Scientific consistencyanalysis covered answer patterns for 51-74 students and 60 inputs for ChatGPT and Gemini, both at the level of single items and answer patterns across items within the test package. Based on average scores, capabilities,and scientific consistency of students and AI were categorized into three levels, as presented in Table 4.
Table 4. Categorization of Capabilities and Scientific Consistency
| Level | Criteria (%) | Category |
| I | 85 – 100 | Capable/consistent |
| II | between 60 – 85 | Moderately capable/moderately consistent |
| III | 0 – 60 | Incapable/inconsistent |
This categorization is arbitrary but aligns with the approach used in the Force Concept Inventory (FCI). A score of 60% on the FCI is considered the "entry threshold" for Newtonian physics, while 85% represents the "mastery threshold" (Hestenes&Halloun, 1995; Nieminen et al., 2010). Although it is referred to as an arbitrary categorization, the classification used by Hestenes and Halloun (1995) is a well-established one that has been widely adopted by researchers in the fields of physics education. The FCI and its categorization are highly popular and widely recognized in the physics education community. The test employed in this study shares similarities with the FCI in that both are designed to probe conceptual understanding; therefore, the categorization used in the FCI can also be applied to the test used in this research.
To evaluate scientific consistency, the average score for each theme or group of items was calculated. This means that scores for each item within a group are summed and then divided by the maximum possible score for the group, resulting in an average score ranging from 0 to 1. For example, in group A, which consists of 4 item pairs or 8 items (maximum score is 8), the subject's score for that group is the sum of all item scores divided by the maximum score. The underlying assumption is that a respondent’s answer to one item should be supported by their answers to other items within the same group (theme, concept, or context). A respondent is considered consistent if a correct answer to one item is also accompanied by correct answers to other items in the same group. Beyond paired scores, the scientific consistency of respondents is also assessed through combined Tier-1 and Tier-2 scores based on item groups. A rubric for assessing the scientific consistency is presented in Table 5.
Table 5. Rubric for assessing the scientific consistency of subjects based on individual items in each group
| Item Group | Maximum score | Level I (Consistent) | Level II(Moderately consistent) | Level III (Inconsistent) |
| A (2 x 4 items) | 8,0 | ≥ 6,8 | 4,8 - 6,8 | ≤ 4,8 |
| B (2 x 6 items) | 12,0 | ≥ 10,2 | 7,2 - 10,2 | ≤ 7,2 |
| C (2 x 9 items) | 18,0 | ≥ 15,3 | 10,8 - 15,3 | ≤ 10,8 |
| D (2 x 4 items) | 8,0 | ≥ 6,8 | 4,8 - 6,8 | ≤ 4,8 |
| E (2 x 2 items) | 4,0 | ≥ 2,4 | 2,4 – 3,4 | ≤ 2,4 |
All scores obtained using the rubric are converted to a 0–100 scale (in %).
Results
Capability of ChatGPT and Gemini
ChatGPTs, Gemini’s, and students’ capabilities in answering the two-tier test differ from one another. The test results, including individual, combined, and paired responses, are descriptively presented in Figure 1. The test results are expressed as mean scores, reflecting the capabilities of each subject.
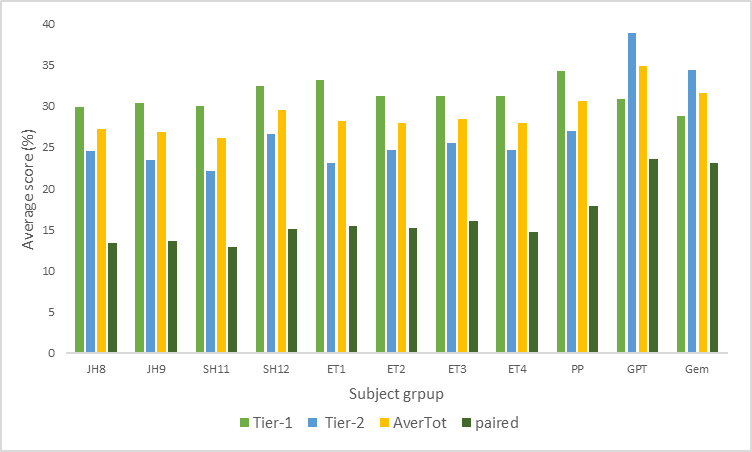
Figure 1. Average Score Diagram of Subjects on Individual Items, Combined Items, and Paired Items
Figure 1 indicates that the average capability scores of ChatGPT, Gemini, and students are categorized as low. For individual, combined, and paired items, all respondents fell below the "entry threshold" of 60% (Hestenes & Halloun, 1995; Nieminen et al., 2010).
Welch ANOVA and post hoc Games-Howell atp< .05 (Appendix P, Table P4) revealed that for case-related items (Tier-1 ), there is no significant difference between ChatGPT, Gemini, and the junior (JH8-JH9) and high school (SH11-SH12) student groups. Among students and pre-service teachers (ET1-ET4), no significant differences were observed either. However, both AI models were significantly outperformed by the group of professional program students (PP).
ChatGPT differs significantly from JH, SH, ET, and PP students. Similarly, Gemini also differs significantly from all student groups. However, there is no significant difference between ChatGPT and Gemini. Both ChatGPT and Gemini perform better than allstudentgroups (Appendix P, Table P8).
Based on Figure 1, students and pre-service teachers, descriptively performed better on Tier-1 items compared to Tier-2. In contrast, both ChatGPT and Gemini scored higher on Tier-2 items than on Tier-1. This suggests that ChatGPT and Gemini are better than students at providing theoretically nuanced arguments but are not as effective when responding to specific cases or phenomena in static fluid contexts.
ChatGPT outperformed all subjects, including Gemini, only when the total scores for Tier-1 and Tier-2 were combined. Gemini, on the other hand, only surpassed JH8, JH9, JH11, ET1, and ET2 (Appendix P, Table P12). For paired items, ChatGPT and Gemini outperformed all subjects, with no significant difference between the two AI models (Appendix Q, Table Q4).
The differences among subjects can be explained based on the effect size values (Appendices P and Q). The eta-squared (η²) effect size for Tier-1 is .05, indicating that 5% of the total variance in capability is due to differences among subjects. For Tier-2,η² = .22, meaning that 22% of the total variance in capability is attributable to differences among subjects. The combined Tier-1 and Tier-2η² = .096 indicates that 9.6% of the total variance in capability is due to differences among subjects, while for the paired items, η² = 0.20 shows that 20% of the total variance in capability is explained by differences among subjects.
These trends in performance indicate that although ChatGPT was more accurate on average when considering the complete Tier-1 and Tier-2 scores, both AI systems exhibited similar ability when addressing paired reasoning questions. These results indicate that the coherence of their scientific reasoning may not completely be represented by accuracy alone. To investigate this issue more systematically in the different systems regarding how consistently they keep conceptual understanding (Tier-1) and explanatory justification (Tier-2) logically aligned, a further analysis looks at scientific consistency.
Scientific Consistency Level
Scientific consistency was determined by averaging the scores across the two tiers, summing the scores for each item within the same group. Using these calculations, the proportion of respondents at each consistency level is identified. The proportion of subjects at each consistency level and the average scores for each item group are descriptively presented in Figure 2.

Figure 2. Respondents: Proportion of Achieving Scientific Consistency Levels, Along with the Average Scores of Subjects Across Item Groups
Figure 2 illustrates that only in item Group A did all subjects achieve an average score exceeding 40, with a maximum of 55, except for Gemini, which obtained the lowest average score of 24. The proportion of respondents at Level III (low,inconsistent) remained above 50%, with Gemini being entirely at this level (100%). The second-largest proportion in this group was at Level II (moderately consistent).
In item groups B, C, and D, none of the subjects reached an average score of 40. Notably, in group B, Gemini recorded the lowest average score, barely reaching 7. For Group C, the highest average score was achieved by Gemini, with a score of 37, followed closely by ChatGPT with an average score of 36. Across item groups B, C, D, and E, almost all subjects were classified as Level III. In item group E, only ChatGPT and Gemini managed to exceed an average score of 40. For this group, Gemini showed dominance at Level I (consistent) and Level III (inconsistent). Gemini achieved the highest proportion at Level I in item group E, with over 60% of respondents at this level and an average score of approximately 84. In contrast, ChatGPT had only around 10% at the same level, with an average score of 56.
The overall data imply that a large proportion of subjects were at a low scientific consistency level, with less than 80% of subjects achieving this, except in item group A, where Gemini reached 100%. This means that none of the subjects achieved a score of 65 for 120 prompt inputs, with an average score below 25 (on a 0-100 scale). This was followed by ChatGPT, with 67% of its responses placed at Level III, having an average score of 48. In contrast, for other item groups, the proportion of subjects at Level III was mostly above 80%, with some even reaching 100%.
With a low average capability score (below 40%), as shown in Figure 1, the subjects generally fall under Scientific Consistency Level III. The two graphs confirm each other: low capability results in a low level of scientific consistency, and vice versa, a low level of scientific consistency reflects low capability.
To quantitatively compare, an ANOVA test (with Tukey post-hoc test) was conducted at p < .05 for Group B and a Welch ANOVA test (with Games-Howell post-hoc test) for other groups. The results showed that for item Group A and Group B, ChatGPT was not significantly different from any subjects, while Gemini was lower than all subjects, including ChatGPT (Appendix R, Table 4 and Appendix R, Table R8). For item Group C, both ChatGPT and Gemini outperformed all subjects, with Gemini performing better than ChatGPT (Appendix R, Table R12). In item Group D, ChatGPT scored lower than ET4 and Gemini, with Gemini outperforming all subjects (Appendix R, Table R16). Lastly, in item Group E, both ChatGPT and Gemini outperformed students (Appendix R, Table R20).
For item Groups A and B, ChatGPT does not differ significantly from any other subjects, whereas Gemini differs significantly from all other subjects and has a lower mean score than the others (Appendix R, Tables R4 and R8). For item Group C, both ChatGPT and Gemini differ significantly from the other subjects and outperform them. However, there is no significant difference between ChatGPT and Gemini, with Gemini showing a slightly higher mean score than ChatGPT (Appendix R, Table R12). For item Group D, ChatGPT differs significantly from ET4 and Gemini, with ChatGPT’s mean score being lower than those of the other subjects. Meanwhile, Gemini differs significantly from JH9, SH11, ET4, and ChatGPT, with a higher mean score than JH9, SH11, and ChatGPT but lower than ET4 (Appendix R, Table R16). For item Group E, both ChatGPT and Gemini differ significantly from the other subjects, with higher mean scores than all others, and Gemini’s mean score is higher than ChatGPT’s (Appendix R, Table R20).
Differences among subjects within each Group can be explained by η² effect size values. The eta-squared effect sizes for item Groups A, B, C, and E fall into the large category. This indicates that a substantial proportion of the total variation in consistency is due to differences among subjects (JH8, JH9, SH11, SH12, ET1, ET2, ET3, ET4, PP, GPT, and Gemini), with eta-squared values as shown in Appendix R. Specifically, 19%, 16%, 23%, and 80% of the total variance are attributed to differences among subjects in item Groups A, B, C, and E, respectively. The effect size for item Group D falls into the medium category, indicating that the total variation in scientific consistency due to differences among subjects in Group D is moderate, with an eta-squared value of .06. This means that 6% of the total variance is caused by differences among subjects in item Group D.
Considering effect sizes among all five conceptual groups, it is clear that some of the respondents were more interpretable based on a “standard” they used. Group A yields a small effect size, indicating that the representation of objects in fluid diagrams is relatively well-understood and would produce similar reasoning patterns across respondent groups. Group B also hardly affects this tendency, implying that the understanding of floating objects and relations between densities is reasonably intuitive and does not significantly distinguish between levels of scientific consistency. For Group C, the slightly larger effect size indicates that the range of consistency has increased even more as items are interpreted for their properties during certain manipulations. A very small effect is found for Group D, demonstrating that the respondents basically shared the same understanding of the modified-object representations. To the contrary, Group E has a high effect size, which can be considered that, despite no significant differences being found among groups in receptive vocabulary subtests, as proposed earlier, a fluid concept that encompasses multiple facets produces a large impact on conceptual reasoning among groups. In general, the overall trend shows that with increasing level of conceptual complexity (from item Groups A to E), the variation in student understanding becomes more diverse. This kind of pattern also suggests that higher-order physical integration would require deeper conceptual processing, and this result helps to distinguish AI from human scientific consistency more directly.
To examine the consistency of scientific reasoning in more detail, a comparison was made between ChatGPT and Gemini using a single subject, SH11. The graphical comparison of the three subjects is descriptively presented in Figure 3. The interpretation focuses on comparing subjects per item group, analysing how one item relates to another. For example, responses to items in the context of floating versus the context of suspending under the same treatment.
Figure 3. Individual scores for ChatGPT-4o, Gemini, and SH11 based on item group
In Figure 3, we illustrate the performance of ChatGPT, Gemini,and SH11 on Tier-1 and Tier-2. In Tier-1 ,only item 13 had an average above 85 for ChatGPT,and items 1, 6, 9, 16, and 25 did for Gemini. In Tier-2, ChatGPT violated 1, 2, 6, 9, 16, and 21 as well as item 25, whereas Gemini did so on items 1, 2, 6, 9, 16, 21, 24, and 25. ChatGPT reached a perfect score (100) on item 1b, and Gemini on items 9b and 25b.
The human participant (SH11) exceeded 85 only for items 1a and 2a, with scores of 98 and 95. Gemini performed better than ChatGPT in some items of Tier-1,with a rating greater than 85. This trend was also observed in Tier-2, but both AIs had very low overall averages (less than 40), indicating little consistency. Figure 3 replicates the pattern of Figure 1 and shows that, in general, both AIs performed better for Tier-2 than for Tier-1, with a few exceptions.
Both AIs also had a zero average score for some Tier-2 items, such as 7a (which was not the case for SH11). For item 9a (hollow object filled with water), the values for ChatGPT and Gemini were 73 and 100, respectively, assuming the hollow object will sink. On the justified claim (Tier-2, item 9b), ChatGPT scored 93 and Gemini 100,which gives consistent reasoning in this example. The dialogue description for item 9's context is presented in Figure S1 (Appendix S).
Interestingly, for the case of a hollow object suspended in air (item 8a), ChatGPT only scored an average of 3, while Gemini scored 50. Both AI systems dominantly chose the answer that filling the hollow with air causes the object to float or remain suspended. In Tier-2 (item 8b), ChatGPT scored an average of 17, and Gemini scored 33. According to ChatGPT, filling the hollow with air makes the object float because the density of air is lower than the density of water. On the other hand, Gemini argued that since the hollow object was initially floating in the water (where density is almost the same as the density of water), when the hollow is filled with air (which has less density than water), the buoyant force acting on the object will still be greater than the object's weight. As a result, the object will remain suspended. The prompt responses from both AIs are presented in Figure S2 (Appendix S).
The inconsistency between the two AIs is evident in cases still relevant to Figures 4 and 5, specifically for hollow objects that are either sinking or floating and then have their hollows filled with air. For example, Figure S3 (Appendix S) presents the prompt given and ChatGPT's response to the case of a hollow object with sinking properties. Figure S4 (Appendix S) presents the prompt given and Gemini's response to the case of a hollow object with floating properties.
Figure S3 reinforces the previous explanation that filling the hollow of an object with air reduces its density. ChatGPT also explained this by comparing the density of air with the density of water. Furthermore, ChatGPT justified this using Archimedes' law,stating that an object will float if it has a density less than the density of the liquid in which it is immersed.
Following a similar pattern to ChatGPT, Gemini responded to the question about the effect of filling air into the hollow of a floating object. Gemini stated that the air affects the submerged volume in water decreases. Gemini also compared the density of air with the density of water and provided justification using the term "upward force." The phrase "the submerged volume in water decreases" was used to indicate that the object's buoyancy increases. Gemini argued that filling the hollow with air reduces the overall density of the object. To clarify this further, a confirmatory question was posed (Figure S5, Appendix S). It appears that Gemini equated the meaning of the statement "buoyancy increases" with "upward force increases."
Discussion
This research presents data on the capabilities and scientific consistency of two generative AIs, ChatGPT and Gemini. Both AIs demonstrated superior capability compared to students in providing reasoning for selecting specific answers. The higher average scores in Tier-2 than in Tier-1 indicate that the AIs predominantly exhibit a false-negative condition rather than a false-positive one. False-negative means that while the answer is incorrect, the reasoning is correct, whereas false-positive occurs when the answer is correct, but the reasoning is incorrect (Aldazharova et al., 2024). This categorization aligns with the perspectives of Bayrak (2013), Caleon and Subramaniam (2010a, 2010b), Chang et al. (2007), and Xiao et al. (2018), who suggested that higher Tier-2 scores compared to Tier-1 reflect an ability to provide reasoning at a higher level of reasoning rather than merely answering questions correctly. Conversely, students predominantly exhibited a false-positive condition rather than a false-negative, as indicated by higher average scores in Tier-1 compared to Tier-2. In this case, students tended to correctly select an option even though they lacked proper reasoning to justify their choice. Although it cannot be generalized, a false-positive may imply the occurrence ofa misconception, whereas a false-negative may lead anindividual towards a correct conception. When a person gives a correct answer without understanding the underlying concept, it indicates the presence of a hidden misconception. When a person gives an incorrect answer despite demonstrating scientific reasoning, it reflects a conceptual thinking process that is moving toward a correct understanding (a transitional or developing conception).
The lower average scores in Tier-1 compared to Tier-2 indicate that ChatGPT and Gemini are not yet well-trained to respond to specific physics case-based items, particularly involving static fluid phenomena. This can be attributed to the understanding that both AIs are developed using large language models (LLMs) and trained to process digital information available on the internet as their database. Despite their low capability (below 40%), the AI shows higher mean Tier-2 scores than Tier-1when explaining theoretical aspects than when addressing physics cases or phenomena that are rarely available online.
The variation and low average scores of ChatGPT, Gemini, and students across items within the same group illustrate their low scientific consistency, which is context-dependent. A subject is considered consistent if their average scores within the same group of items (context) reach 85 or higher and do not differ significantly from each other. Low total average scores (below 40), combined with some items scoring above 85 or even 100, along with high standard deviations, underscore this variation. For example, there is no significant difference between objects floating with holes and those that are submerged, provided they receive the same treatment. However, both AIs predominantly perceive them differently.
The most extreme example lies in cases where a hollow is filled with air or water. Ideally, there should be no difference in the two contexts, as both relate to the effect of adding a substance to an object on its density. Uniquely, subjects believe that filling a hollow with water increases density, whereas filling it with air decreases it. ChatGPT and Gemini (as well as students) primarily compare the density of air to that of water. The lower density of air compared to water leads to the assumption that the object’s overall density decreases. This reflects the subjects' inconsistency. Adding water to the hollow of a suspended object causes it to sink, while adding air is perceived to make it float. These findings reinforce previous studies (Mansyur et al., 2022a,2022b), which noted that respondents often compare the density of air to water rather than comprehensively understanding the principle of density and buoyancy.
The extreme variation in average scores, where some items within the same context score 100 while others score 0, reflects the low consistency of AI subjects. From the perspective of accuracy or scientific validity, this inconsistency falls under the category of low scientific consistency. Such low consistency is also evident in the differing average scores across tiers for items within the same group, despite the underlying concept being tested being the same. This variation highlights the dependency of these AI systems on the availability of digital data-based information.
Conceptually, ChatGPT applied Archimedes' law in its analysis. However, comparing the densities of air and water was a misunderstanding, as the object already exhibits specific behaviour in water (e.g., a sinking object with a hollow that is then filled with air). The AI's focus should have been on the effect of filling the hollow with air on the object's mass, subsequently affecting its density. If filling the hollow with air were to reduce the object's mass (while maintaining a constant volume), the response would have been correct. However, no object’s mass decreases when its hollow is filled with air.
If the AI “imagines” air-filling akin to inflating a balloon, which allows it to float or fly in the air, this would constitute an error. For a balloon, air-filling increases the balloon's volume, reducing its overall density and enabling it to float or fly in the air. Initially, researchers doubted ChatGPT's response due to ambiguities in the prompt, which did not specify whether the object’s volume remained constant. A follow-up prompt clarified this, yet ChatGPT's response remained the same, adding an explanation based on the formulaρ=m/Vas justification.
When asked why the density decreased, ChatGPT reasoned that the density decreased because the mass remained constant while the composition changed. By filling the object’s hollow with air, part of the solid material's mass was replaced by air, which has a negligible mass. Since density (ρ=m/V) is the ratio of mass to volume, and the effective mass decreased without a change in volume, the density also decreased, making the object more likely to float in water.
Although ChatGPT consistently followed its reasoning along this line, the reasoning was not scientifically incorrect. This finding corroborates Gregorcic and Pendrill’s (2023) study, which identified that ChatGPT’s reasoning in physics often contained incorrect or contradictory interpretations.
Contradictions in reasoning also appeared in Gemini’s responses. For example, the phrase"the volume of the submerged part of the object decreases" was used to explain that the object becomes more buoyant. Gemini argued that filling the hollow with air reduces the object's overall density. However, when examining items 9 and 8 (which share the same indicator and aspect), Gemini interpreted their implications differently. In the first case, filling the hollow with air causes the object to sink, while in the second case, it causes the object to float.
When we asked why the buoyancy increased, Gemini explained that although the air adds to the object's total mass, the dominant effect that makes the object more buoyant is the increased volume of the object submerged in water. According to Gemini,"When the hollow is filled with air, the volume of the part of the object below the water's surface becomes larger. This causes the object to displace more water, which increases the buoyant force acting on it. This increase in buoyant force is significantly greater than the slight increase in mass due to the air, making the object overall more buoyant."This reasoning revealed contradictions. On the one hand, Gemini claimed that the submerged volume increases, implying a decrease in buoyancy. On the other hand, it stated that the buoyant force increases due to the larger submerged volume, suggesting it applies Archimedes' law but focused solely on the buoyant force without considering the density change. It seems Gemini equated "increased buoyancy" with "increased buoyant force." However, buoyancy strictly relates to a reduction in density, whereas buoyant force depends on the volume of the submerged part of the object. Filling the hollow with air (at a constant volume) increases the object’s density while simultaneously increasing the submerged part, meaning the object’s buoyancy decreases.
Based on the explanation above, although ChatGPT and Gemini demonstrated some similar capabilities in Tier-1, Tier-2, and paired items, ChatGPT significantly outperforms Gemini when viewing both tiers of each item as a unified set. This finding aligns with previous research that highlighted ChatGPT's superiority over other AI, such as Bing Chat (Vasconcelos & dos Santos, 2023).
The confirmatory dialogues, as discussed earlier, indicate that both generative AI models function as agents for thinking, demonstrating conceptual understanding and domain-specific knowledge. At the same time, models still employed an incorrect reasoning process(Tang & Kejriwal, 2023). Regarding accuracy, this research diverges from earlier findings that reported ChatGPT’s high performance on fact-based questions, with an accuracy rate of 100%, attributed to its ability to accurately gather and summarize information (Cruz et al., 2024; Yanget al., 2023).
This study shows that GPT-4 and Gemini possess the capability to answer questions about static fluid phenomena, albeit at a low level. In terms of accuracy, these findings contrast with previous research indicating high accuracy in ChatGPT and Gemini, such as in a test on the nature of science (Nyaaba, 2024). Regarding insight, understanding, and scientific consistency, both generative AI models display higher-than-average knowledge and comprehension compared to the students. However, despite their superior capability, ChatGPT and Gemini exhibit weaknesses in consistency, where their responses may contain biased or contradictory information.
Recent literature about AI performances in STEM education offers a useful context for discussing results from this study.Kortemeyer(2023) and Kieser et al. (2023) showed that ChatGPT was relatively successful on physics concept inventories and programming exercises but exhibited very erratic reasoning in non-routine tasks. Similarly, Liang et al. (2023) observed that ChatGPT can generate reasonable physics answers, while often providing partial or tautological causal explanations. Thesestudiesconfirm the above results of the current study, where AI systems demonstrate partial concept comprehension and variability in their reasoning accuracy.
Comparative studies on multimodal systems with new knowledge, such as Gemini, demonstrate gains in factual elements at the cost of reasoning. Rane et al. (2024) and Jere (2025) found that the integration with immediate experience offered by Gemini (real-time data input) favors precision of factual reminiscence but not that of consistent conceptual interpretation. This is consistent with the present static fluid reasoning results in which both ChatGPT and Gemini showed correct theoretical grounding but inconsistent application within like-contexts. This consistency across studies indicates that AI’s conceptual variability is a systematic property, rather than simply the artefact of task construction.
The inconsistencies found in ChatGPT and Gemini can be explained through theoretical perspectives on LLM behaviour. As probabilistic text predictors, LLMs generate responses based on statistical patterns rather than causal reasoning (Kandpalet al., 2023). This explains why their answers often appear coherent but fail to maintain logical consistency across contexts that require physical or mechanistic understanding. The inconsistency arises from the structural gap between linguistic fluency and conceptual grounding, where an inherent limitation of current AI architectures is optimized for language correlation rather than scientific causality.
From a cognitive modelling standpoint, these inconsistencies reflect what Bubeck et al. (2023) describe as “emergent reasoning without grounding.” LLMs can simulate reasoning chains resembling human thought, yet their explanations fluctuate when the input context lies outside familiar data distributions. This behaviour aligns with the notion of contextual overfitting, where AI performs accurately in well-represented scenarios but inconsistently in novel or counterintuitive ones. The variation of ChatGPT’s (Werdhiana et al., 2025)and Gemini’s reasoning in static fluid contexts exemplifies this limitation.
Viewed epistemologically, such inconsistencies represent the boundary of AI as a data-driven reasoning system. Generative models reconstruct meaning from linguistic associations rather than from experiential understanding of scientific principles (Vasconcelos & dos Santos, 2023). Consequently, their reasoning appears to be probabilistic rather than conceptual. Recognizing this limitation allows AI-generated responses to be interpreted not as cognitive errors but as reflections of how language-based intelligence approximates scientific reasoning within the constraints of its training data.
The pedagogical inference from this research means that AI should not be an information source but a metacognitive coagent stimulating reasoning and reflection. The instabilities in ChatGPT and Gemini can be put to constructive work through inquiry-based and Socratic dialogue. By reflecting on and criticizing AI-produced explanations, students become better able to distinguish between linguistically convincing reasoning and genuinely scientific reasoning. This reflection enhances the comprehension of concepts, encourages critical thinking,and develops scientific literacy in STEM.
From a practical perspective, teachers can use AI as directed feedback mechanisms for formative assessment and diagnosis. The two-tier test format (as used in the present study) provides teachers with a comparison between student explanations and AI explanations of science concepts within their responses to gauge misconceptions for subsequent instruction. Instead of depending on AI as a respondent, educators need to view it as a dialogic support structure for engaging questioning, reasoning,and conceptual development. AI, therefore, acts as a pedagogical sense-making tool to foster deeper engagement and reflective learning in science classrooms.
This work makes the following contributions to the literature by introducing an empirical framework to assess the capability and scientific consistency of large language models with a two-tier test. By contrast to the prior study that constrained AI to merely explain its accuracy, this research addresses how AI systems reason, justify, and maintain conceptual coherence by comparing them with human learners. Through characterizing ChatGPT and Gemini as learner analogues, the work demonstrates new insights about AI’s reasoning and paves the way for combining diagnostic and reflective uses of AI within STEM education.
Conclusion
This study explored two research questions: the extent to which ChatGPT’s and Gemini’s capabilities and scientific consistency were compared to human learners, and the reasoning patterns and types of inconsistencies demonstrated by each AI when responding to a two-tier test of static fluid. Both ChatGPT and Gemini seemed to display higher capability and scientific consistency in comparison to junior, senior high school, elementary school teacher education, and elementary school teacher professional programs. However, the absolute performance remained below the entry threshold, indicating that their absolute knowledge domains were not yet complete. The effect sizes of the differences between AI and human participants were, as a rule, small, with ChatGPT leading only in the combined Tier-1 and Tier-2 scores and Gemini leading in categorical factual recall. Thus, while AIs seemed more capable of putting into words theoretical reasoning, they still lacked a strong grasp of the domain and a proper feel for context. The reasoning patterns, both systems, seemed to be inclined in the direction of a false negative: valid reasoning often accompanied the incorrect answer, while the human participants’ profiles were directed as false positives, where correct answers were rather baseless. While ChatGPT's reasoning reflected coherence over logic here and there for purely language-based reasons, Gemini demonstrated precision of facts but a lack of contextual soundness in their application over multiple contexts. Thus, both models signified probable rather than mechanical reasoning modes, and their scientific consistency wobbled with the correctness and language frame.
Recommendation
As AIs built with large language models, ChatGPT and Gemini are highly dependent on theavailability of information from digital data on the internet and require larger and more varied databases containing cases in the context of static fluid. Understanding the capabilities, consistency, limitations, and reasoning behaviour of ChatGPT and Gemini is useful as a foundation for selecting and utilizing AI in a proportional and selective manner according to specific needs.Both AI capability and scientific consistency are assessed empirically in this work through a two-tier test, where AI is placed in the role of a learner analogue. Future research should extend this framework to other scientific domains, with adaptive prompting and multimodal reasoning adaptation, and the work of teacher–AI co-assessment models for AI’s conceptual reliability and pedagogical usefulness. Also, Future study is recommended to align AI dialogue with students’ verbal protocols in order to compare their respective reasoning pathways.
Limitation
In addition to exposing contradictions and biases in AI thinking, the study also specifies several limitations related to design. Although every ChatGPT and Gemini prompting session was independent and randomly chosen, full conversational independence cannot be fully assured, as subtle residual contextual memory or system-level calibration may influence replies. Since there was also an inconsistent format for prompts and neither was its registration checked, this increased operational unreliability in terms of replicability and comparability across sessions.
The current study limited its scope to issues of static fluid, thus also limiting external validity and generalizability of results from our scientific study to others besides itself. Because both AI models undergo continuous training and are updated with new information, their thinking behavior can be expected to change over time. It might produce different results under identical conditions in the future. Thus, interpretation of present findings should even more be seen as time- and context-bound.
Funding
This research received financial support from the Directorate General of Higher Education, Research, and Technology under the Ministry of Education, Culture, Research, and Technology of the Republic of Indonesia, through Contract No. 095/E5/PG.02.00.PL/2024.
We thank all the students for their valuable time to participate in this research.
Authorship Contribution Statement
Kaharu: Study concept and design, acquisition of data, analysis, and interpretation of data, critical revision of manuscript reviewing.Werdhiana:Study concept and design, acquisition of data, analysis, and interpretation of data.Mansyur:Study concept and design, acquisition of data, analysisand interpretation of data, drafting of manuscript, critical revision of manuscript, andfinal approval.